 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Locality in Hierarchical Recursive Reasoning
May 20, 2026Spatial reasoning requires both location-bound computation and location-invariant structure: agents must make local moves while preserving route, object, or constraint-level plans. We propose interaction locality, a task-geometry-aware framework for measuring whether information flow stays within nearby cells or semantic segments, or crosses them. We instantiate the framework with sparse-autoencoder feature ablations and finite-noise activation patching, with structural Jacobian and attention checks reported in the appendix, and apply it to HRM and TRM, two compact hierarchical and recursive reasoning models, on Maze-Hard, Sudoku Extreme, and ARC-AGI. Across these models, activation patching gives the clearest architectural fingerprint: high-level recurrent states tend to write information within nearby cells or same-segment units, while repeated recursive updates accumulate these local writes into broader solution structure. This pattern holds across maze paths, Sudoku constraints, and ARC-AGI object neighborhoods, with the strongest concentration in TRM. To test whether interaction locality extends beyond toy-yet-challenging grid benchmarks, we also apply it to MTU3D, a large-scale embodied 3D scene-grounding model. In this MTU3D setting, causal spatial locality appears primarily at the transition where visual scene features are handed to the downstream grounding module, rather than uniformly throughout the visual encoder. This contrast suggests that the local-to-global handoff observed in HRM and TRM is tied to explicit recursive reasoning dynamics, while embodied 3D models may concentrate causal spatial structure at module boundaries. Interaction locality turns the intuitive local-execution/global-planning story into a reproducible measurement framework for recursive and embodied spatial reasoning.
Superficial Consciousness Hypothesis for Autoregressive Transformers
Dec 10, 2024The alignment between human objectives and machine learning models built on these objectives is a crucial yet challenging problem for achieving Trustworthy AI, particularly when preparing for superintelligence (SI). First, given that SI does not exist today, empirical analysis for direct evidence is difficult. Second, SI is assumed to be more intelligent than humans, capable of deceiving us into underestimating its intelligence, making output-based analysis unreliable. Lastly, what kind of unexpected property SI might have is still unclear. To address these challenges, we propose the Superficial Consciousness Hypothesis under Information Integration Theory (IIT), suggesting that SI could exhibit a complex information-theoretic state like a conscious agent while unconscious. To validate this, we use a hypothetical scenario where SI can update its parameters "at will" to achieve its own objective (mesa-objective) under the constraint of the human objective (base objective). We show that a practical estimate of IIT's consciousness metric is relevant to the widely used perplexity metric, and train GPT-2 with those two objectives. Our preliminary result suggests that this SI-simulating GPT-2 could simultaneously follow the two objectives, supporting the feasibility of the Superficial Consciousness Hypothesis.
Multimodal Contrastive In-Context Learning
Aug 23, 2024
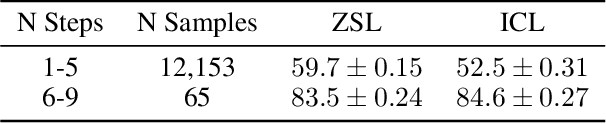

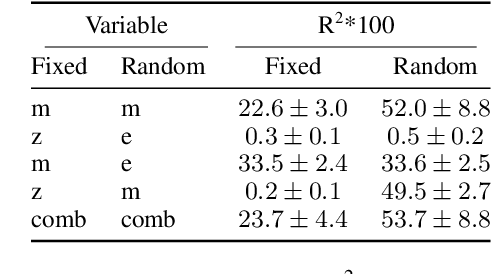
The rapid growth of Large Language Models (LLMs) usage has highlighted the importance of gradient-free in-context learning (ICL). However, interpreting their inner workings remains challenging. This paper introduces a novel multimodal contrastive in-context learning framework to enhance our understanding of ICL in LLMs. First, we present a contrastive learning-based interpretation of ICL in real-world settings, marking the distance of the key-value representation as the differentiator in ICL. Second, we develop an analytical framework to address biases in multimodal input formatting for real-world datasets. We demonstrate the effectiveness of ICL examples where baseline performance is poor, even when they are represented in unseen formats. Lastly, we propose an on-the-fly approach for ICL (Anchored-by-Text ICL) that demonstrates effectiveness in detecting hateful memes, a task where typical ICL struggles due to resource limitations. Extensive experiments on multimodal datasets reveal that our approach significantly improves ICL performance across various scenarios, such as challenging tasks and resource-constrained environments. Moreover, it provides valuable insights into the mechanisms of in-context learning in LLMs. Our findings have important implications for developing more interpretable, efficient, and robust multimodal AI systems, especially in challenging tasks and resource-constrained environments.
Causal Intersectionality and Dual Form of Gradient Descent for Multimodal Analysis: a Case Study on Hateful Memes
Aug 19, 2023In the wake of the explosive growth of machine learning (ML) usage, particularly within the context of emerging Large Language Models (LLMs), comprehending the semantic significance rooted in their internal workings is crucial. While causal analyses focus on defining semantics and its quantification, the gradient-based approach is central to explainable AI (XAI), tackling the interpretation of the black box. By synergizing these approaches, the exploration of how a model's internal mechanisms illuminate its causal effect has become integral for evidence-based decision-making. A parallel line of research has revealed that intersectionality - the combinatory impact of multiple demographics of an individual - can be structured in the form of an Averaged Treatment Effect (ATE). Initially, this study illustrates that the hateful memes detection problem can be formulated as an ATE, assisted by the principles of intersectionality, and that a modality-wise summarization of gradient-based attention attribution scores can delineate the distinct behaviors of three Transformerbased models concerning ATE. Subsequently, we show that the latest LLM LLaMA2 has the ability to disentangle the intersectional nature of memes detection in an in-context learning setting, with their mechanistic properties elucidated via meta-gradient, a secondary form of gradient. In conclusion, this research contributes to the ongoing dialogue surrounding XAI and the multifaceted nature of ML models.