 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPSA-FSR: Simultaneous Perturbation Stochastic Approximation for Feature Selection and Ranking
Apr 16, 2018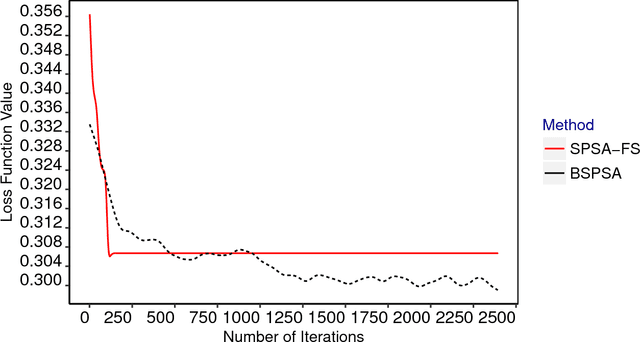
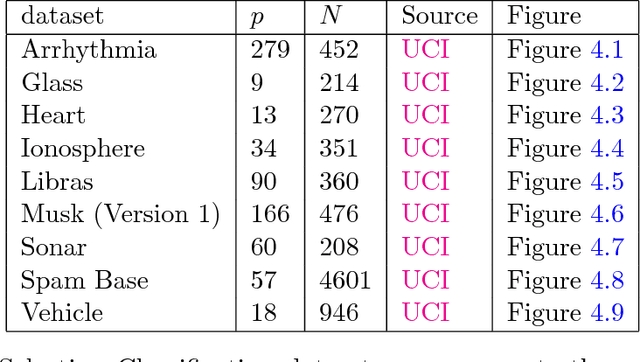
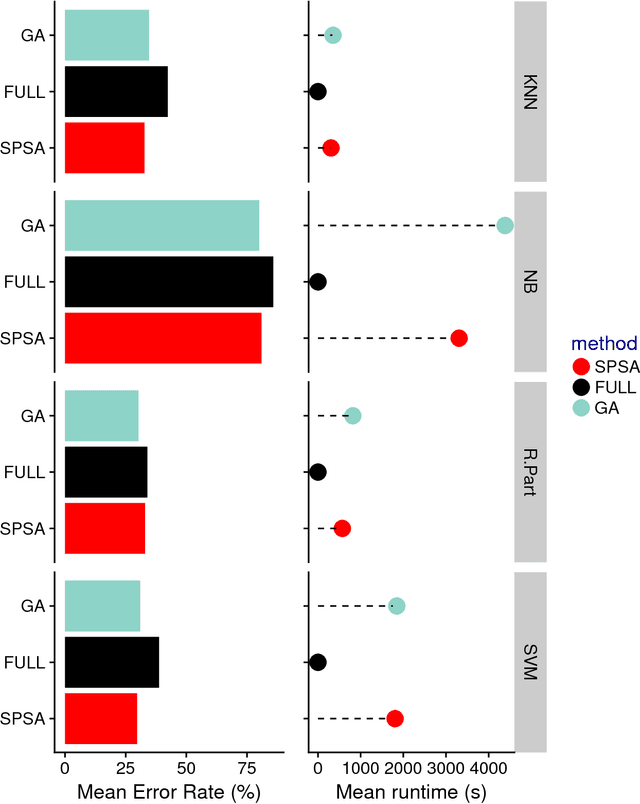
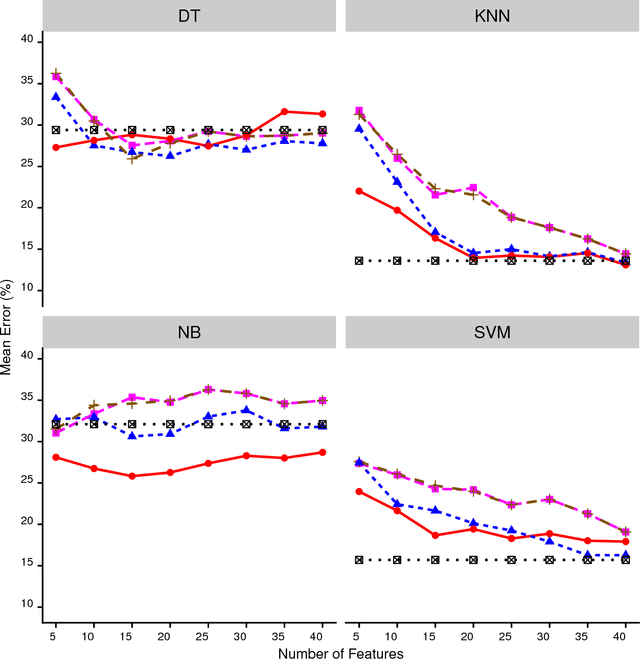
This manuscript presents the following: (1) an improved version of the Binary Simultaneous Perturbation Stochastic Approximation (SPSA) Method for feature selection in machine learning (Aksakalli and Malekipirbazari, Pattern Recognition Letters, Vol. 75, 2016) based on non-monotone iteration gains computed via the Barzilai and Borwein (BB) method, (2) its adaptation for feature ranking, and (3) comparison against popular methods on public benchmark datasets. The improved method, which we call SPSA-FSR, dramatically reduces the number of iterations required for convergence without impacting solution quality. SPSA-FSR can be used for feature ranking and feature selection both for classification and regression problems. After a review of the current state-of-the-art, we discuss our improvements in detail and present three sets of computational experiments: (1) comparison of SPSA-FS as a (wrapper) feature selection method against sequential methods as well as genetic algorithms, (2) comparison of SPSA-FS as a feature ranking method in a classification setting against random forest importance, chi-squared, and information main methods, and (3) comparison of SPSA-FS as a feature ranking method in a regression setting against minimum redundancy maximum relevance (MRMR), RELIEF, and linear correlation methods. The number of features in the datasets we use range from a few dozens to a few thousands. Our results indicate that SPSA-FS converges to a good feature set in no more than 100 iterations and therefore it is quite fast for a wrapper method. SPSA-FS also outperforms popular feature selection as well as feature ranking methods in majority of test cases, sometimes by a large margin, and it stands as a promising new feature selection and ranking method.