 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Around and Refer: 2D Synthetic Semantics Knowledge Distillation for 3D Visual Grounding
Nov 25, 2022


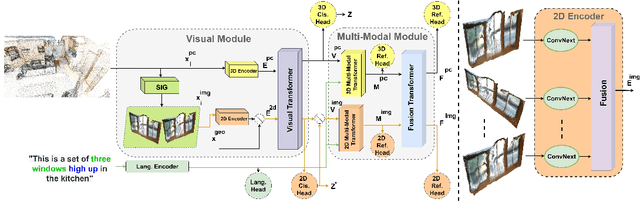
The 3D visual grounding task has been explored with visual and language streams comprehending referential language to identify target objects in 3D scenes. However, most existing methods devote the visual stream to capturing the 3D visual clues using off-the-shelf point clouds encoders. The main question we address in this paper is "can we consolidate the 3D visual stream by 2D clues synthesized from point clouds and efficiently utilize them in training and testing?". The main idea is to assist the 3D encoder by incorporating rich 2D object representations without requiring extra 2D inputs. To this end, we leverage 2D clues, synthetically generated from 3D point clouds, and empirically show their aptitude to boost the quality of the learned visual representations. We validate our approach through comprehensive experiments on Nr3D, Sr3D, and ScanRefer datasets and show consistent performance gains compared to existing methods. Our proposed module, dubbed as Look Around and Refer (LAR), significantly outperforms the state-of-the-art 3D visual grounding techniques on three benchmarks, i.e., Nr3D, Sr3D, and ScanRefer. The code is available at https://eslambakr.github.io/LAR.github.io/.