 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing movies to predict their commercial viability for producers
Jan 05, 2021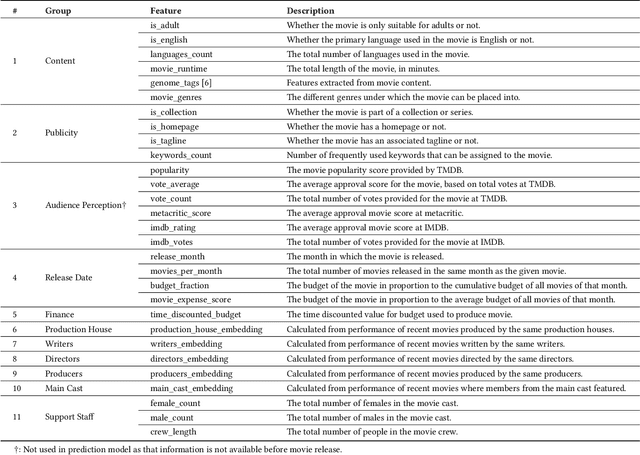
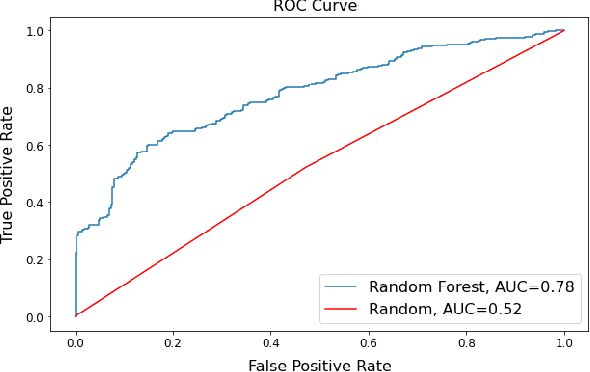
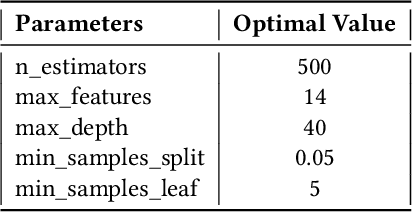
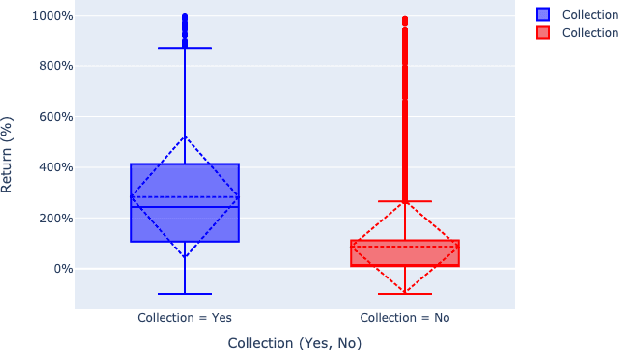
Upon film premiere, a major form of speculation concerns the relative success of the film. This relativity is in particular regards to the film's original budget, as many a time have big-budget blockbusters been met with exceptional success as met with abject failure. So how does one predict the success of an upcoming film? In this paper, we explored a vast array of film data in an attempt to develop a model that could predict the expected return of an upcoming film. The approach to this development is as follows: First, we began with the MovieLens dataset having common movie attributes along with genome tags per each film. Genome tags give insight into what particular characteristics of the film are most salient. We then included additional features regarding film content, cast/crew, audience perception, budget, and earnings from TMDB, IMDB, and Metacritic websites. Next, we performed exploratory data analysis and engineered a wide range of new features capturing historical information for the available features. Thereafter, we used singular value decomposition (SVD) for dimensionality reduction of the high dimensional features (ex. genome tags). Finally, we built a Random Forest Classifier and performed hyper-parameter tuning to optimize for model accuracy. A future application of our model could be seen in the film industry, allowing production companies to better predict the expected return of their projects based on their envisioned outline for their production procedure, thereby allowing them to revise their plan in an attempt to achieve optimal returns.