 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free sparse attention based on cumulative energy filtering
Jun 15, 2026Sparse attention accelerates Diffusion Transformers (DiTs) for video generation by computing only the important tokens while skipping the rest. The token selection strategy is key to balancing sparsity and accuracy. We formulate the token filtering process as a dual-goal optimization problem: maximizing sparsity and minimizing accuracy degradation. Existing algorithms cannot fulfill both objectives simultaneously. For example, Top-p only considers the accuracy constraint, while Top-k maintains a fixed computational budget but loosens the accuracy constraint. This paper demonstrates that maintaining a fixed recall rate is sufficient for ensuring accuracy, whereas a fixed threshold is suboptimal for reducing computational cost. Therefore, we propose a dynamic thresholding scheme to improve sparsity while maintaining the same level of accuracy. Furthermore, our algorithm is deeply integrated with Flash Attention (FA), eliminating the need for any additional masking computation overhead. Experimental results on Wan 2.2 validate that, compared to the BLASST algorithm which is also integrated with FA, our dynamic thresholding strategy enhances sparsity from 61.42\% to 82\% with a VBench metric drop of less than 5\%. This results in an approximate 15\% in attention computation and a $1.61\times$ increase in computational efficiency, which is 1.18x higher than that of BLASST.
VFA: Relieving Vector Operations in Flash Attention with Global Maximum Pre-computation
Apr 14, 2026FlashAttention-style online softmax enables exact attention computation with linear memory by streaming score tiles through on-chip memory and maintaining a running maximum and normalizer. However, as attention kernels approach peak tensor-core/cube-core throughput on modern accelerators, non-matmul components of online softmax -- especially per-tile rowmax and rowsum reductions and rescale chains -- can become vector or SIMD limited and dominate latency. This paper revisits FlashAttention and proposes Vector Relieved Flash Attention (VFA), a hardware-friendly method that reduces rowmax-driven updates of the running maximum while retaining the online-softmax structure. VFA initializes the running maximum via a cheap approximation from key-block representations, reorders key-block traversal to prioritize high-impact sink and local blocks, and freezes the maximum for remaining blocks to avoid repeated reductions and rescaling. We further integrate VFA with block-sparse skipping methods such as BLASST to form Vector Relieved Sparse Attention (VSA), which reduces both block count and per-block overhead. Notably, VFA and VSA completely avoid the conditional rescale operation in the update stage used in FA4.0. Extensive evaluations on benchmarks including MMLU and MATH500, together with attention statistics, verify our design: (i) sink and local reordering stabilizes the running maximum early; (ii) simple Q and K block summaries fail due to intra-block heterogeneity; (iii) m-initialization is required when maxima appear in middle blocks. Overall, VFA and VSA efficiently alleviate online-softmax reduction bottlenecks without performance loss. Compared to the C16V32 baseline, C8V32, C4V32 and C4V16 achieve nearly two times speedup on modern hardware while hitting the vector bottleneck. With upcoming architecture improvements, C4V16 will deliver six times speedup by enhancing exponent capacity.
OSC: Hardware Efficient W4A4 Quantization via Outlier Separation in Channel Dimension
Apr 14, 2026While 4-bit quantization is essential for high-throughput deployment of Large Language Models, activation outliers often lead to significant accuracy degradation due to the restricted dynamic range of low-bit formats. In this paper, we systematically investigate the spatial distribution of outliers and demonstrate a token-persistent structural clustering effect, where high-magnitude outliers consistently occupy fixed channels across tokens. Building on this insight, we propose OSC, a hardware-efficient framework for outlier suppression. During inference, OSC executes a dual-path computation consisting of a low-precision 4-bit General Matrix Multiplication (GEMM) path and a high-precision 16-bit branch GEMM path. Specifically, OSC uses an offline group-wise strategy to identify the channels where outliers are located and then performs structured sub-tensor extraction to coalesce these scattered activation channels into a compact dense tensor online. This mechanism implements outlier protection through regularized and high-throughput GEMM operations, achieving a seamless fit with modern 4-bit micro-scaling hardware. Furthermore, for the inputs of W2 where outlier clustering is less pronounced, we integrate a fallback strategy to FP8. Evaluation on Qwen3-8B and Qwen3-30B restricts the average accuracy drop to 2.19 and 1.12 points, respectively. Notably, OSC is highly hardware-friendly, achieving a peak speedup of 1.78x over the W8A8 GEMM baseline on a modern AI accelerator.
Tourism Demand Forecasting with Tourist Attention: An Ensemble Deep Learning Approach
Mar 10, 2020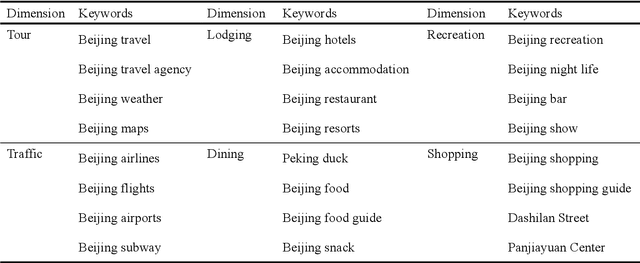

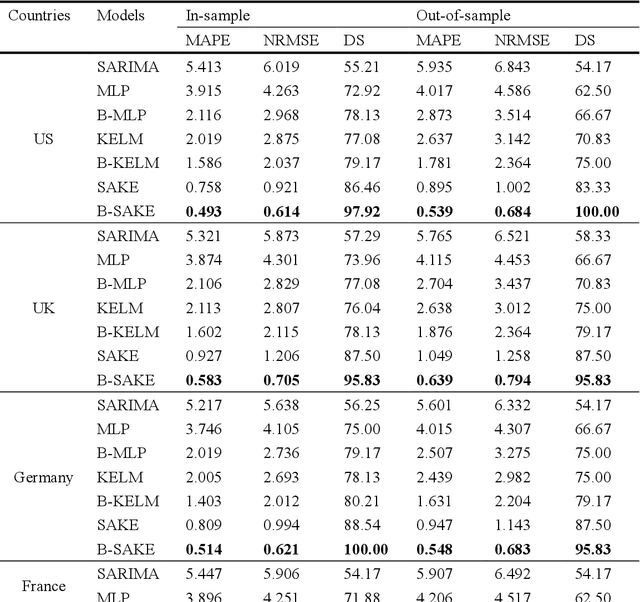
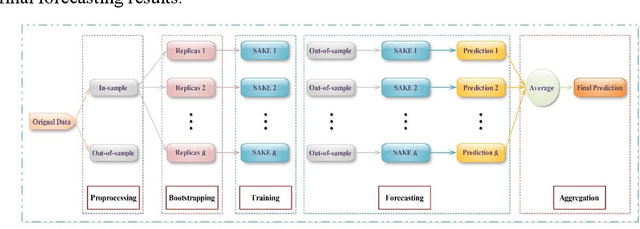
The large amount of tourism-related data presents a series of challenges for tourism demand forecasting, including data deficiencies, multicollinearity and long calculation times. A bagging-based multivariate ensemble deep learning approach integrating stacked autoencoders and kernel-based extreme learning machines (B-SAKE) is proposed to address these challenges in this study. We forecast tourist arrivals in Beijing from four countries by adopting historical data on tourist arrivals in Beijing, economic indicators and online tourist behavior variables. The results from the cases of four origin countries suggest that our proposed B-SAKE approach outperforms than benchmark models in terms of horizontal accuracy, directional accuracy and statistical significance. Both bagging and stacked autoencoder can improve the forecasting performance of the models. Moreover, the forecasting performance of the models is evaluated with consistent results by means of the multi-step-ahead forecasting scheme.