 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Adaptive Rank Space Exploration for Efficient Sentiment Analysis with Large Language Models
Oct 22, 2024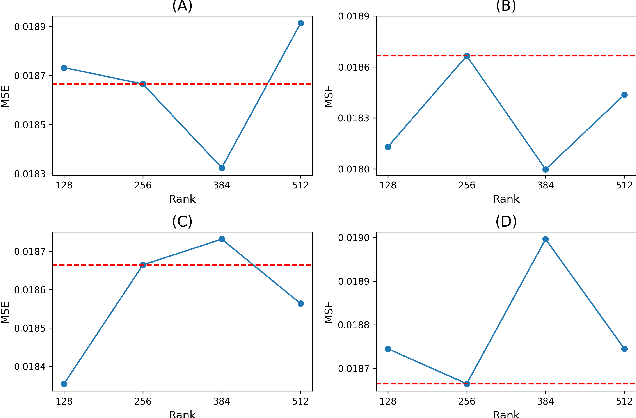
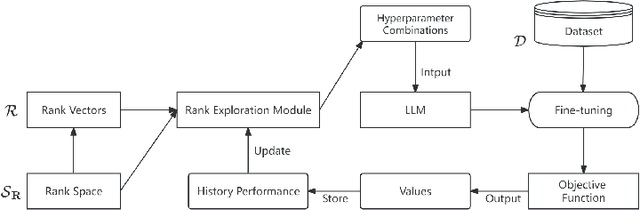


Sentiment analysis has become increasingly important for assessing public opinion and informing decision-making. Large language models (LLMs) have revolutionized this field by capturing nuanced language patterns. However, adapting LLMs to domain-specific sentiment analysis tasks remains challenging due to computational constraints and the need for optimal fine-tuning. To address these challenges, we propose a novel Dynamic Adaptive Rank Space Exploration (DARSE) framework for efficient and effective sentiment analysis using LLMs. DARSE consists of a coarse-grained greedy algorithm to identify the optimal rank range, a fine-grained exploration algorithm to refine rank selection, and a dynamic rank allocation method to determine the optimal rank combination for each LLM layer. Extensive experiments demonstrate that DARSE significantly improves sentiment analysis accuracy, achieving a 15.1% improvement in MSE and a 4.3% improvement in accuracy compared to previous work. Our framework strikes a balance between computational efficiency and model performance, making it a promising approach for sentiment analysis with LLMs.
EUR-USD Exchange Rate Forecasting Based on Information Fusion with Large Language Models and Deep Learning Methods
Aug 23, 2024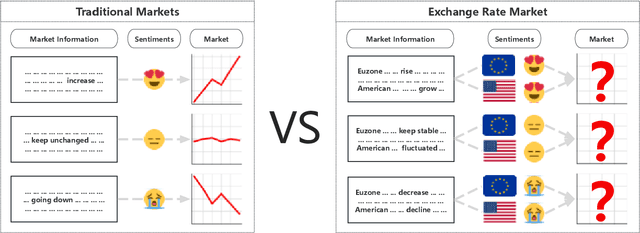
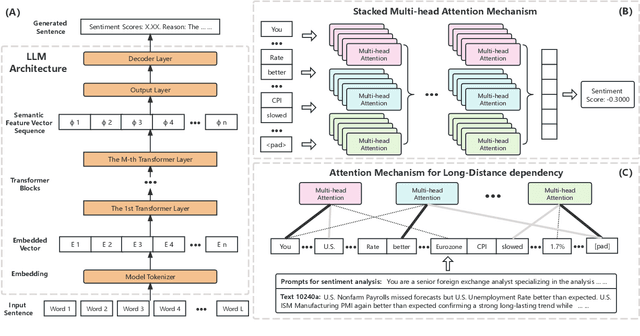
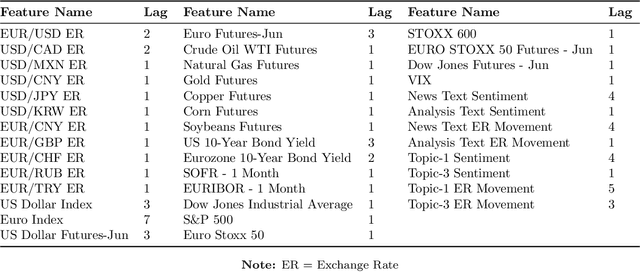
Accurate forecasting of the EUR/USD exchange rate is crucial for investors, businesses, and policymakers. This paper proposes a novel framework, IUS, that integrates unstructured textual data from news and analysis with structured data on exchange rates and financial indicators to enhance exchange rate prediction. The IUS framework employs large language models for sentiment polarity scoring and exchange rate movement classification of texts. These textual features are combined with quantitative features and input into a Causality-Driven Feature Generator. An Optuna-optimized Bi-LSTM model is then used to forecast the EUR/USD exchange rate. Experiments demonstrate that the proposed method outperforms benchmark models, reducing MAE by 10.69% and RMSE by 9.56% compared to the best performing baseline. Results also show the benefits of data fusion, with the combination of unstructured and structured data yielding higher accuracy than structured data alone. Furthermore, feature selection using the top 12 important quantitative features combined with the textual features proves most effective. The proposed IUS framework and Optuna-Bi-LSTM model provide a powerful new approach for exchange rate forecasting through multi-source data integration.
Dynamic Adaptive Optimization for Effective Sentiment Analysis Fine-Tuning on Large Language Models
Aug 15, 2024



Sentiment analysis plays a crucial role in various domains, such as business intelligence and financial forecasting. Large language models (LLMs) have become a popular paradigm for sentiment analysis, leveraging multi-task learning to address specific tasks concurrently. However, LLMs with fine-tuning for sentiment analysis often underperforms due to the inherent challenges in managing diverse task complexities. Moreover, constant-weight approaches in multi-task learning struggle to adapt to variations in data characteristics, further complicating model effectiveness. To address these issues, we propose a novel multi-task learning framework with a dynamic adaptive optimization (DAO) module. This module is designed as a plug-and-play component that can be seamlessly integrated into existing models, providing an effective and flexible solution for multi-task learning. The key component of the DAO module is dynamic adaptive loss, which dynamically adjusts the weights assigned to different tasks based on their relative importance and data characteristics during training. Sentiment analyses on a standard and customized financial text dataset demonstrate that the proposed framework achieves superior performance. Specifically, this work improves the Mean Squared Error (MSE) and Accuracy (ACC) by 15.58% and 1.24% respectively, compared with previous work.