 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning Framework for Stock Selection
Aug 08, 2018

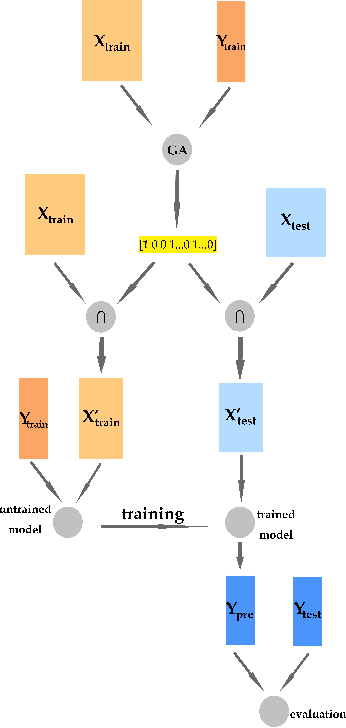

This paper demonstrates how to apply machine learning algorithms to distinguish good stocks from the bad stocks. To this end, we construct 244 technical and fundamental features to characterize each stock, and label stocks according to their ranking with respect to the return-to-volatility ratio. Algorithms ranging from traditional statistical learning methods to recently popular deep learning method, e.g. Logistic Regression (LR), Random Forest (RF), Deep Neural Network (DNN), and the Stacking, are trained to solve the classification task. Genetic Algorithm (GA) is also used to implement feature selection. The effectiveness of the stock selection strategy is validated in Chinese stock market in both statistical and practical aspects, showing that: 1) Stacking outperforms other models reaching an AUC score of 0.972; 2) Genetic Algorithm picks a subset of 114 features and the prediction performances of all models remain almost unchanged after the selection procedure, which suggests some features are indeed redundant; 3) LR and DNN are radical models; RF is risk-neutral model; Stacking is somewhere between DNN and RF. 4) The portfolios constructed by our models outperform market average in back tests.
Language Distribution Prediction based on Batch Markov Monte Carlo Simulation with Migration
Feb 26, 2018Language spreading is a complex mechanism that involves issues like culture, economics, migration, population etc. In this paper, we propose a set of methods to model the dynamics of the spreading system. To model the randomness of language spreading, we propose the Batch Markov Monte Carlo Simulation with Migration(BMMCSM) algorithm, in which each agent is treated as a language stack. The agent learns languages and migrates based on the proposed Batch Markov Property according to the transition matrix T and migration matrix M. Since population plays a crucial role in language spreading, we also introduce the Mortality and Fertility Mechanism, which controls the birth and death of the simulated agents, into the BMMCSM algorithm. The simulation results of BMMCSM show that the numerical and geographic distribution of languages varies across the time. The change of distribution fits the world cultural and economic development trend. Next, when we construct Matrix T, there are some entries of T can be directly calculated from historical statistics while some entries of T is unknown. Thus, the key to the success of the BMMCSM lies in the accurate estimation of transition matrix T by estimating the unknown entries of T under the supervision of the known entries. To achieve this, we first construct a 20 by 20 by 5 factor tensor X to characterize each entry of T. Then we train a Random Forest Regressor on the known entries of T and use the trained regressor to predict the unknown entries. The reason why we choose Random Forest(RF) is that, compared to Single Decision Tree, it conquers the problem of over fitting and the Shapiro test also suggests that the residual of RF subjects to the Normal distribution.