 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Pre-trained Models for Failure Analysis Triplets Generation
Oct 31, 2022

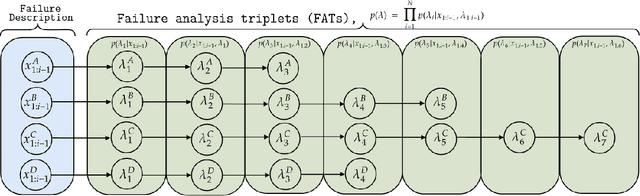

Pre-trained Language Models recently gained traction in the Natural Language Processing (NLP) domain for text summarization, generation and question-answering tasks. This stems from the innovation introduced in Transformer models and their overwhelming performance compared with Recurrent Neural Network Models (Long Short Term Memory (LSTM)). In this paper, we leverage the attention mechanism of pre-trained causal language models such as Transformer model for the downstream task of generating Failure Analysis Triplets (FATs) - a sequence of steps for analyzing defected components in the semiconductor industry. We compare different transformer models for this generative task and observe that Generative Pre-trained Transformer 2 (GPT2) outperformed other transformer model for the failure analysis triplet generation (FATG) task. In particular, we observe that GPT2 (trained on 1.5B parameters) outperforms pre-trained BERT, BART and GPT3 by a large margin on ROUGE. Furthermore, we introduce Levenshstein Sequential Evaluation metric (LESE) for better evaluation of the structured FAT data and show that it compares exactly with human judgment than existing metrics.
GCVAE: Generalized-Controllable Variational AutoEncoder
Jun 09, 2022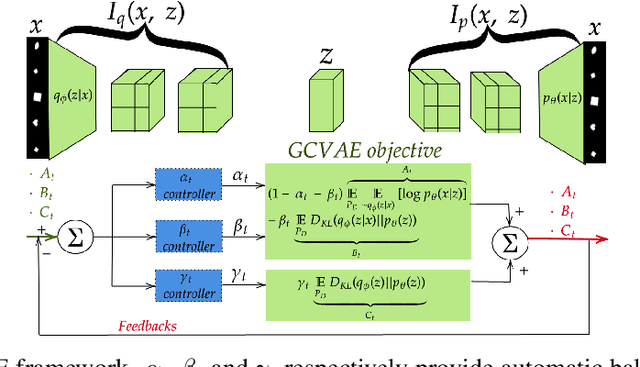



Variational autoencoders (VAEs) have recently been used for unsupervised disentanglement learning of complex density distributions. Numerous variants exist to encourage disentanglement in latent space while improving reconstruction. However, none have simultaneously managed the trade-off between attaining extremely low reconstruction error and a high disentanglement score. We present a generalized framework to handle this challenge under constrained optimization and demonstrate that it outperforms state-of-the-art existing models as regards disentanglement while balancing reconstruction. We introduce three controllable Lagrangian hyperparameters to control reconstruction loss, KL divergence loss and correlation measure. We prove that maximizing information in the reconstruction network is equivalent to information maximization during amortized inference under reasonable assumptions and constraint relaxation.