 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying The Effect of MIL Pooling Filters on MIL Tasks
Jun 02, 2020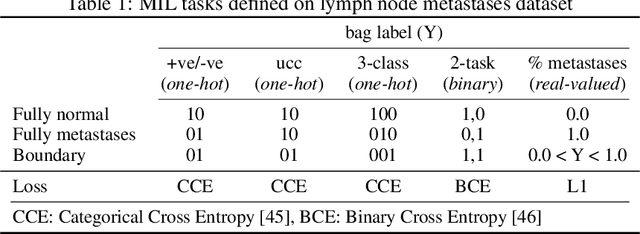
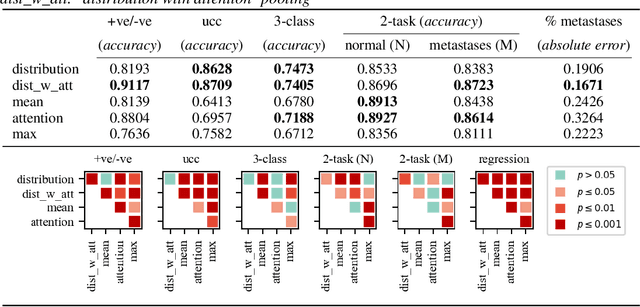
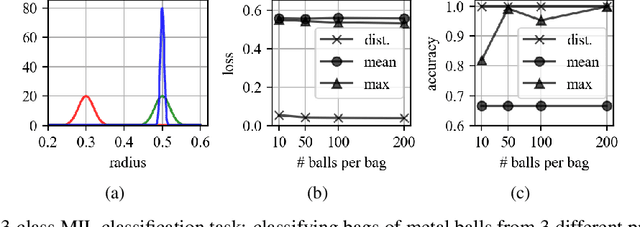
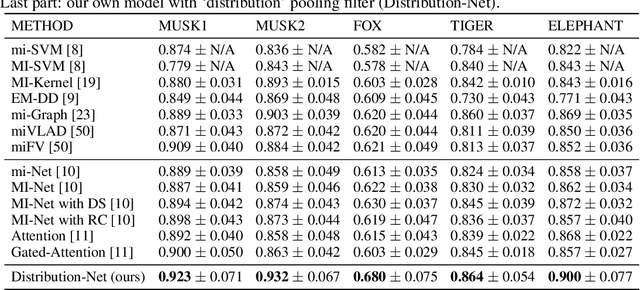
There are different multiple instance learning (MIL) pooling filters used in MIL models. In this paper, we study the effect of different MIL pooling filters on the performance of MIL models in real world MIL tasks. We designed a neural network based MIL framework with 5 different MIL pooling filters: `max', `mean', `attention', `distribution' and `distribution with attention'. We also formulated 5 different MIL tasks on a real world lymph node metastases dataset. We found that the performance of our framework in a task is different for different filters. We also observed that the performances of the five pooling filters are also different from task to task. Hence, the selection of a correct MIL pooling filter for each MIL task is crucial for better performance. Furthermore, we noticed that models with `distribution' and `distribution with attention' pooling filters consistently perform well in almost all of the tasks. We attribute this phenomena to the amount of information captured by `distribution' based pooling filters. While point estimate based pooling filters, like `max' and `mean', produce point estimates of distributions, `distribution' based pooling filters capture the full information in distributions. Lastly, we compared the performance of our neural network model with `distribution' pooling filter with the performance of the best MIL methods in the literature on classical MIL datasets and our model outperformed the others.
A Weakly Supervised Learning Based Clustering Framework
Jun 18, 2019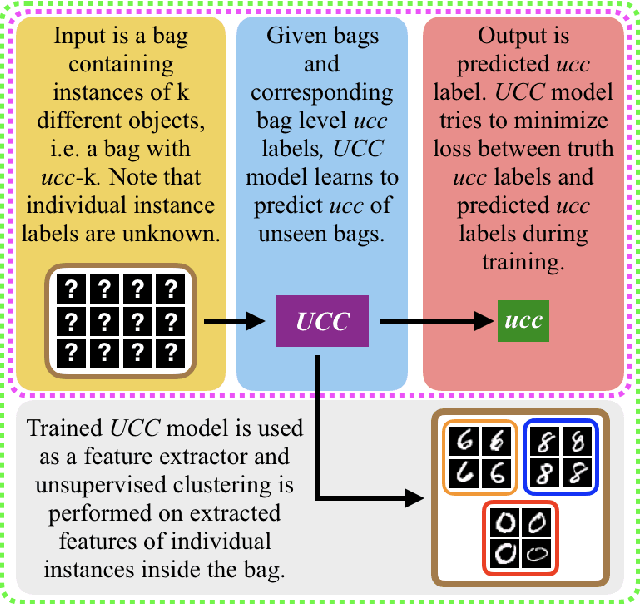
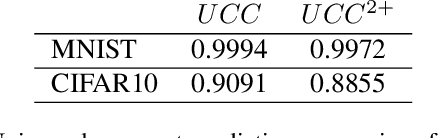
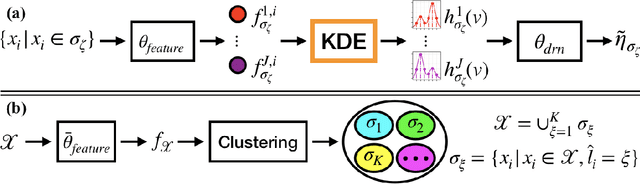
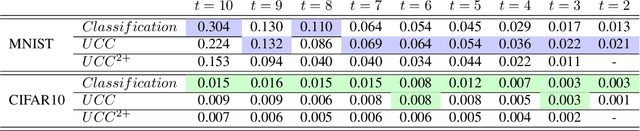
A weakly supervised learning based clustering framework is proposed in this paper. As the core of this framework, we introduce a novel multiple instance learning task based on a bag level label called unique class count ($ucc$), which is the number of unique classes among all instances inside the bag. In this task, no annotations on individual instances inside the bag are needed during training of the models. We mathematically prove that a perfect $ucc$ classifier, in principle, can be used to perfectly cluster individual instances inside the bags. In other words, perfect clustering of individual instances is possible even when no annotations on individual instances are given during training. We have constructed a neural network based $ucc$ classifier and experimentally shown that the clustering performance of our framework with our $ucc$ classifier is comparable to that of fully supervised learning models. We have also observed that our $ucc$ classifiers can potentially be used for zero-shot learning as they learn better semantic features than fully supervised models for `unseen classes', which have never been input into the models during training.
An Even Faster and More Unifying Algorithm for Comparing Trees via Unbalanced Bipartite Matchings
Jan 18, 2001


A widely used method for determining the similarity of two labeled trees is to compute a maximum agreement subtree of the two trees. Previous work on this similarity measure is only concerned with the comparison of labeled trees of two special kinds, namely, uniformly labeled trees (i.e., trees with all their nodes labeled by the same symbol) and evolutionary trees (i.e., leaf-labeled trees with distinct symbols for distinct leaves). This paper presents an algorithm for comparing trees that are labeled in an arbitrary manner. In addition to this generality, this algorithm is faster than the previous algorithms. Another contribution of this paper is on maximum weight bipartite matchings. We show how to speed up the best known matching algorithms when the input graphs are node-unbalanced or weight-unbalanced. Based on these enhancements, we obtain an efficient algorithm for a new matching problem called the hierarchical bipartite matching problem, which is at the core of our maximum agreement subtree algorithm.