 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Redundancies in Time Series Foundation Models
Feb 02, 2026Time Series Foundation Models (TSFMs) leverage extensive pretraining to accurately predict unseen time series during inference, without the need for task-specific fine-tuning. Through large-scale evaluations on standard benchmarks, we find that leading transformer-based TSFMs exhibit redundant components in their intermediate layers. We introduce a set of tools for mechanistic interpretability of TSFMs, including ablations of specific components and direct logit attribution on the residual stream. Our findings are consistent across several leading TSFMs with diverse architectures, and across a diverse set of real-world and synthetic time-series datasets. We discover that all models in our study are robust to ablations of entire layers. Furthermore, we develop a theoretical framework framing transformers as kernel regressors, motivating a purely intrinsic strategy for ablating heads based on the stable rank of the per-head projection matrices. Using this approach, we uncover the specific heads responsible for degenerate phenomena widely observed in TSFMs, such as parroting of motifs from the context and seasonality bias. Our study sheds light on the universal properties of this emerging class of architectures for continuous-time sequence modeling.
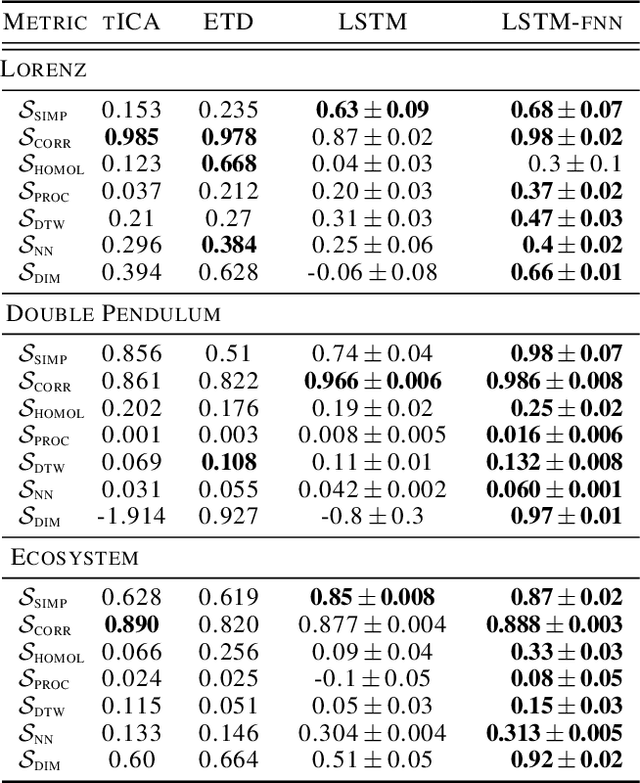
Panda: A pretrained forecast model for universal representation of chaotic dynamics
May 19, 2025Chaotic systems are intrinsically sensitive to small errors, challenging efforts to construct predictive data-driven models of real-world dynamical systems such as fluid flows or neuronal activity. Prior efforts comprise either specialized models trained separately on individual time series, or foundation models trained on vast time series databases with little underlying dynamical structure. Motivated by dynamical systems theory, we present Panda, Patched Attention for Nonlinear DynAmics. We train Panda on a novel synthetic, extensible dataset of $2 \times 10^4$ chaotic dynamical systems that we discover using an evolutionary algorithm. Trained purely on simulated data, Panda exhibits emergent properties: zero-shot forecasting of unseen real world chaotic systems, and nonlinear resonance patterns in cross-channel attention heads. Despite having been trained only on low-dimensional ordinary differential equations, Panda spontaneously develops the ability to predict partial differential equations without retraining. We demonstrate a neural scaling law for differential equations, underscoring the potential of pretrained models for probing abstract mathematical domains like nonlinear dynamics.
Context parroting: A simple but tough-to-beat baseline for foundation models in scientific machine learning
May 16, 2025Recently-developed time series foundation models for scientific machine learning exhibit emergent abilities to predict physical systems. These abilities include zero-shot forecasting, in which a model forecasts future states of a system given only a short trajectory as context. Here, we show that foundation models applied to physical systems can give accurate predictions, but that they fail to develop meaningful representations of the underlying physics. Instead, foundation models often forecast by context parroting, a simple zero-shot forecasting strategy that copies directly from the context. As a result, a naive direct context parroting model scores higher than state-of-the-art time-series foundation models on predicting a diverse range of dynamical systems, at a tiny fraction of the computational cost. We draw a parallel between context parroting and induction heads, which explains why large language models trained on text can be repurposed for time series forecasting. Our dynamical systems perspective also ties the scaling between forecast accuracy and context length to the fractal dimension of the attractor, providing insight into the previously observed in-context neural scaling laws. Context parroting thus serves as a simple but tough-to-beat baseline for future time-series foundation models and can help identify in-context learning strategies beyond parroting.
The cell as a token: high-dimensional geometry in language models and cell embeddings
Mar 26, 2025Single-cell sequencing technology maps cells to a high-dimensional space encoding their internal activity. This process mirrors parallel developments in machine learning, where large language models ingest unstructured text by converting words into discrete tokens embedded within a high-dimensional vector space. This perspective explores how advances in understanding the structure of language embeddings can inform ongoing efforts to analyze and visualize single cell datasets. We discuss how the context of tokens influences the geometry of embedding space, and the role of low-dimensional manifolds in shaping this space's robustness and interpretability. We highlight new developments in language modeling, such as interpretability probes and in-context reasoning, that can inform future efforts to construct and consolidate cell atlases.
Zero-shot forecasting of chaotic systems
Sep 24, 2024Time-series forecasting is a challenging task that traditionally requires specialized models custom-trained for the specific task at hand. Recently, inspired by the success of large language models, foundation models pre-trained on vast amounts of time-series data from diverse domains have emerged as a promising candidate for general-purpose time-series forecasting. The defining characteristic of these foundation models is their ability to perform zero-shot learning, that is, forecasting a new system from limited context data without explicit re-training or fine-tuning. Here, we evaluate whether the zero-shot learning paradigm extends to the challenging task of forecasting chaotic systems. Across 135 distinct chaotic dynamical systems and $10^8$ timepoints, we find that foundation models produce competitive forecasts compared to custom-trained models (including NBEATS, TiDE, etc.), particularly when training data is limited. Interestingly, even after point forecasts fail, foundation models preserve the geometric and statistical properties of the chaotic attractors, demonstrating a surprisingly strong ability to capture the long-term behavior of chaotic dynamical systems. Our results highlight the promises and pitfalls of foundation models in making zero-shot forecasts of chaotic systems.
Generative learning for nonlinear dynamics
Nov 07, 2023Modern generative machine learning models demonstrate surprising ability to create realistic outputs far beyond their training data, such as photorealistic artwork, accurate protein structures, or conversational text. These successes suggest that generative models learn to effectively parametrize and sample arbitrarily complex distributions. Beginning half a century ago, foundational works in nonlinear dynamics used tools from information theory to infer properties of chaotic attractors from time series, motivating the development of algorithms for parametrizing chaos in real datasets. In this perspective, we aim to connect these classical works to emerging themes in large-scale generative statistical learning. We first consider classical attractor reconstruction, which mirrors constraints on latent representations learned by state space models of time series. We next revisit early efforts to use symbolic approximations to compare minimal discrete generators underlying complex processes, a problem relevant to modern efforts to distill and interpret black-box statistical models. Emerging interdisciplinary works bridge nonlinear dynamics and learning theory, such as operator-theoretic methods for complex fluid flows, or detection of broken detailed balance in biological datasets. We anticipate that future machine learning techniques may revisit other classical concepts from nonlinear dynamics, such as transinformation decay and complexity-entropy tradeoffs.
Large statistical learning models effectively forecast diverse chaotic systems
Mar 13, 2023Chaos and unpredictability are traditionally synonymous, yet recent advances in statistical forecasting suggest that large machine learning models can derive unexpected insight from extended observation of complex systems. Here, we study the forecasting of chaos at scale, by performing a large-scale comparison of 24 representative state-of-the-art multivariate forecasting methods on a crowdsourced database of 135 distinct low-dimensional chaotic systems. We find that large, domain-agnostic time series forecasting methods based on artificial neural networks consistently exhibit strong forecasting performance, in some cases producing accurate predictions lasting for dozens of Lyapunov times. Best-in-class results for forecasting chaos are achieved by recently-introduced hierarchical neural basis function models, though even generic transformers and recurrent neural networks perform strongly. However, physics-inspired hybrid methods like neural ordinary equations and reservoir computers contain inductive biases conferring greater data efficiency and lower training times in data-limited settings. We observe consistent correlation across all methods despite their widely-varying architectures, as well as universal structure in how predictions decay over long time intervals. Our results suggest that a key advantage of modern forecasting methods stems not from their architectural details, but rather from their capacity to learn the large-scale structure of chaotic attractors.
Recurrences reveal shared causal drivers of complex time series
Jan 31, 2023Many experimental time series measurements share an unobserved causal driver. Examples include genes targeted by transcription factors, ocean flows influenced by large-scale atmospheric currents, and motor circuits steered by descending neurons. Reliably inferring this unseen driving force is necessary to understand the intermittent nature of top-down control schemes in diverse biological and engineered systems. Here, we introduce a new unsupervised learning algorithm that uses recurrences in time series measurements to gradually reconstruct an unobserved driving signal. Drawing on the mathematical theory of skew-product dynamical systems, we identify recurrence events shared across response time series, which implicitly define a recurrence graph with glass-like structure. As the amount or quality of observed data improves, this recurrence graph undergoes a percolation transition manifesting as weak ergodicity breaking for random walks on the induced landscape -- revealing the shared driver's dynamics, even in the presence of strongly corrupted or noisy measurements. Across several thousand random dynamical systems, we empirically quantify the dependence of reconstruction accuracy on the rate of information transfer from a chaotic driver to the response systems, and we find that effective reconstruction proceeds through gradual approximation of the driver's dominant unstable periodic orbits. Through extensive benchmarks against classical and neural-network-based signal processing techniques, we demonstrate our method's strong ability to extract causal driving signals from diverse real-world datasets spanning neuroscience, genomics, fluid dynamics, and physiology.
Chaos as an interpretable benchmark for forecasting and data-driven modelling
Oct 11, 2021



The striking fractal geometry of strange attractors underscores the generative nature of chaos: like probability distributions, chaotic systems can be repeatedly measured to produce arbitrarily-detailed information about the underlying attractor. Chaotic systems thus pose a unique challenge to modern statistical learning techniques, while retaining quantifiable mathematical properties that make them controllable and interpretable as benchmarks. Here, we present a growing database currently comprising 131 known chaotic dynamical systems spanning fields such as astrophysics, climatology, and biochemistry. Each system is paired with precomputed multivariate and univariate time series. Our dataset has comparable scale to existing static time series databases; however, our systems can be re-integrated to produce additional datasets of arbitrary length and granularity. Our dataset is annotated with known mathematical properties of each system, and we perform feature analysis to broadly categorize the diverse dynamics present across the collection. Chaotic systems inherently challenge forecasting models, and across extensive benchmarks we correlate forecasting performance with the degree of chaos present. We also exploit the unique generative properties of our dataset in several proof-of-concept experiments: surrogate transfer learning to improve time series classification, importance sampling to accelerate model training, and benchmarking symbolic regression algorithms.
* 10 pages, 4 figures, plus appendices
Deep learning of dynamical attractors from time series measurements
Feb 14, 2020


Experimental measurements of physical systems often have a finite number of independent channels, causing essential dynamical variables to remain unobserved. However, many popular methods for unsupervised inference of latent dynamics from experimental data implicitly assume that the measurements have higher intrinsic dimensionality than the underlying system---making coordinate identification a dimensionality reduction problem. Here, we study the opposite limit, in which hidden governing coordinates must be inferred from only a low-dimensional time series of measurements. Inspired by classical techniques for studying the strange attractors of chaotic systems, we introduce a general embedding technique for time series, consisting of an autoencoder trained with a novel latent-space loss function. We first apply our technique to a variety of synthetic and real-world datasets with known strange attractors, and we use established and novel measures of attractor fidelity to show that our method successfully reconstructs attractors better than existing techniques. We then use our technique to discover dynamical attractors in datasets ranging from patient electrocardiograms, to household electricity usage, to eruptions of the Old Faithful geyser---demonstrating diverse applications of our technique for exploratory data analysis.