 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDarkStream: real-time speech anonymization with low latency
Sep 04, 2025We propose DarkStream, a streaming speech synthesis model for real-time speaker anonymization. To improve content encoding under strict latency constraints, DarkStream combines a causal waveform encoder, a short lookahead buffer, and transformer-based contextual layers. To further reduce inference time, the model generates waveforms directly via a neural vocoder, thus removing intermediate mel-spectrogram conversions. Finally, DarkStream anonymizes speaker identity by injecting a GAN-generated pseudo-speaker embedding into linguistic features from the content encoder. Evaluations show our model achieves strong anonymization, yielding close to 50% speaker verification EER (near-chance performance) on the lazy-informed attack scenario, while maintaining acceptable linguistic intelligibility (WER within 9%). By balancing low-latency, robust privacy, and minimal intelligibility degradation, DarkStream provides a practical solution for privacy-preserving real-time speech communication.
Disentangling segmental and prosodic factors to non-native speech comprehensibility
Aug 20, 2024Current accent conversion (AC) systems do not disentangle the two main sources of non-native accent: segmental and prosodic characteristics. Being able to manipulate a non-native speaker's segmental and/or prosodic channels independently is critical to quantify how these two channels contribute to speech comprehensibility and social attitudes. We present an AC system that not only decouples voice quality from accent, but also disentangles the latter into its segmental and prosodic characteristics. The system is able to generate accent conversions that combine (1) the segmental characteristics from a source utterance, (2) the voice characteristics from a target utterance, and (3) the prosody of a reference utterance. We show that vector quantization of acoustic embeddings and removal of consecutive duplicated codewords allows the system to transfer prosody and improve voice similarity. We conduct perceptual listening tests to quantify the individual contributions of segmental features and prosody on the perceived comprehensibility of non-native speech. Our results indicate that, contrary to prior research in non-native speech, segmental features have a larger impact on comprehensibility than prosody. The proposed AC system may also be used to study how segmental and prosody cues affect social attitudes towards non-native speech.
End-to-end Streaming model for Low-Latency Speech Anonymization
Jun 13, 2024Speaker anonymization aims to conceal cues to speaker identity while preserving linguistic content. Current machine learning based approaches require substantial computational resources, hindering real-time streaming applications. To address these concerns, we propose a streaming model that achieves speaker anonymization with low latency. The system is trained in an end-to-end autoencoder fashion using a lightweight content encoder that extracts HuBERT-like information, a pretrained speaker encoder that extract speaker identity, and a variance encoder that injects pitch and energy information. These three disentangled representations are fed to a decoder that resynthesizes the speech signal. We present evaluation results from two implementations of our system, a full model that achieves a latency of 230ms, and a lite version (0.1x in size) that further reduces latency to 66ms while maintaining state-of-the-art performance in naturalness, intelligibility, and privacy preservation.
How to read faces without looking at them
Apr 25, 2020
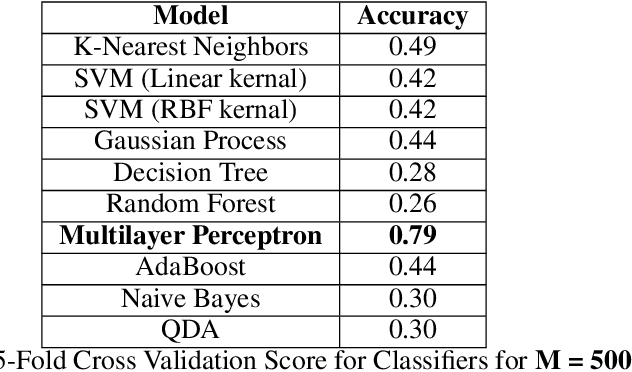
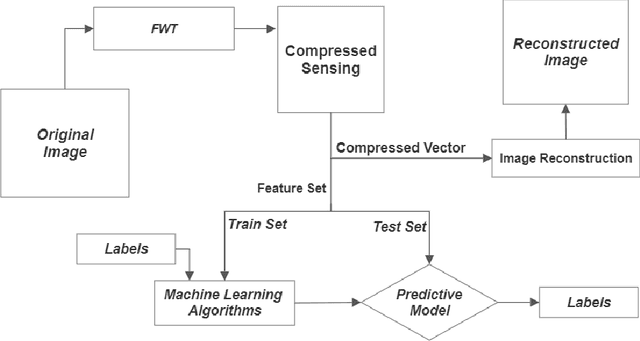

Face reading is the most intuitive aspect of emotion recognition. Unfortunately, digital analysis of facial expression requires digitally recording personal faces. As emotional analysis is particularly required in a more poised scenario, capturing faces becomes a gross violation of privacy. In this paper, we use the concept of compressive analysis to conceptualise a system which compressively acquires faces in order to ascertain unusable reconstruction, while allowing for acceptable (and adjustable) accuracy in inference.