 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis and Optimization of fastText Linear Text Classifier
Feb 17, 2017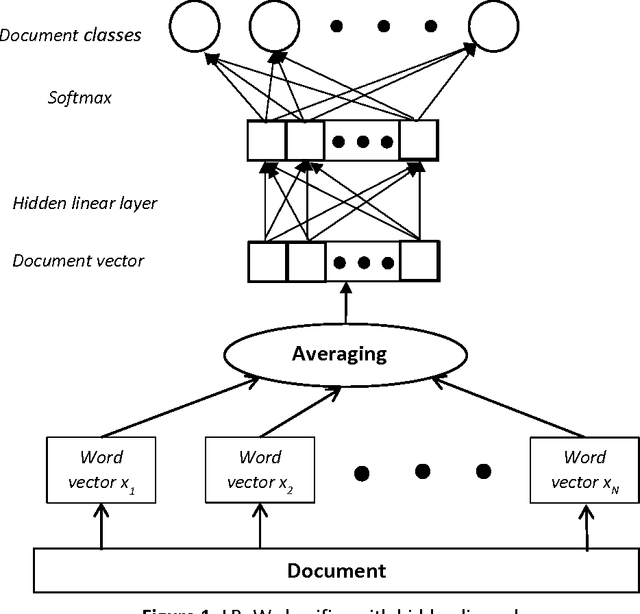
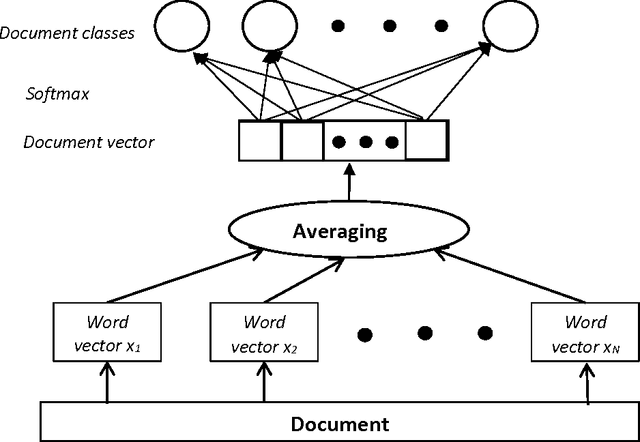
The paper [1] shows that simple linear classifier can compete with complex deep learning algorithms in text classification applications. Combining bag of words (BoW) and linear classification techniques, fastText [1] attains same or only slightly lower accuracy than deep learning algorithms [2-9] that are orders of magnitude slower. We proved formally that fastText can be transformed into a simpler equivalent classifier, which unlike fastText does not have any hidden layer. We also proved that the necessary and sufficient dimensionality of the word vector embedding space is exactly the number of document classes. These results help constructing more optimal linear text classifiers with guaranteed maximum classification capabilities. The results are proven exactly by pure formal algebraic methods without attracting any empirical data.