 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToTMNet: FFT-Accelerated Toeplitz Temporal Mixing Network for Lightweight Remote Photoplethysmography
Jan 07, 2026Remote photoplethysmography (rPPG) estimates a blood volume pulse (BVP) waveform from facial videos captured by commodity cameras. Although recent deep models improve robustness compared to classical signal-processing approaches, many methods increase computational cost and parameter count, and attention-based temporal modeling introduces quadratic scaling with respect to the temporal length. This paper proposes ToTMNet, a lightweight rPPG architecture that replaces temporal attention with an FFT-accelerated Toeplitz temporal mixing layer. The Toeplitz operator provides full-sequence temporal receptive field using a linear number of parameters in the clip length and can be applied in near-linear time using circulant embedding and FFT-based convolution. ToTMNet integrates the global Toeplitz temporal operator into a compact gated temporal mixer that combines a local depthwise temporal convolution branch with gated global Toeplitz mixing, enabling efficient long-range temporal filtering while only having 63k parameters. Experiments on two datasets, UBFC-rPPG (real videos) and SCAMPS (synthetic videos), show that ToTMNet achieves strong heart-rate estimation accuracy with a compact design. On UBFC-rPPG intra-dataset evaluation, ToTMNet reaches 1.055 bpm MAE with Pearson correlation 0.996. In a synthetic-to-real setting (SCAMPS to UBFC-rPPG), ToTMNet reaches 1.582 bpm MAE with Pearson correlation 0.994. Ablation results confirm that the gating mechanism is important for effectively using global Toeplitz mixing, especially under domain shift. The main limitation of this preprint study is the use of only two datasets; nevertheless, the results indicate that Toeplitz-structured temporal mixing is a practical and efficient alternative to attention for rPPG.
Training-Free Color-Aware Adversarial Diffusion Sanitization for Diffusion Stegomalware Defense at Security Gateways
Dec 30, 2025The rapid expansion of generative AI has normalized large-scale synthetic media creation, enabling new forms of covert communication. Recent generative steganography methods, particularly those based on diffusion models, can embed high-capacity payloads without fine-tuning or auxiliary decoders, creating significant challenges for detection and remediation. Coverless diffusion-based techniques are difficult to counter because they generate image carriers directly from secret data, enabling attackers to deliver stegomalware for command-and-control, payload staging, and data exfiltration while bypassing detectors that rely on cover-stego discrepancies. This work introduces Adversarial Diffusion Sanitization (ADS), a training-free defense for security gateways that neutralizes hidden payloads rather than detecting them. ADS employs an off-the-shelf pretrained denoiser as a differentiable proxy for diffusion-based decoders and incorporates a color-aware, quaternion-coupled update rule to reduce artifacts under strict distortion limits. Under a practical threat model and in evaluation against the state-of-the-art diffusion steganography method Pulsar, ADS drives decoder success rates to near zero with minimal perceptual impact. Results demonstrate that ADS provides a favorable security-utility trade-off compared to standard content transformations, offering an effective mitigation strategy against diffusion-driven steganography.
QRetinex-Net: Quaternion-Valued Retinex Decomposition for Low-Level Computer Vision Applications
Jul 22, 2025Images taken in low light often show color shift, low contrast, noise, and other artifacts that hurt computer-vision accuracy. Retinex theory addresses this by viewing an image S as the pixel-wise product of reflectance R and illumination I, mirroring the way people perceive stable object colors under changing light. The decomposition is ill-posed, and classic Retinex models have four key flaws: (i) they treat the red, green, and blue channels independently; (ii) they lack a neuroscientific model of color vision; (iii) they cannot perfectly rebuild the input image; and (iv) they do not explain human color constancy. We introduce the first Quaternion Retinex formulation, in which the scene is written as the Hamilton product of quaternion-valued reflectance and illumination. To gauge how well reflectance stays invariant, we propose the Reflectance Consistency Index. Tests on low-light crack inspection, face detection under varied lighting, and infrared-visible fusion show gains of 2-11 percent over leading methods, with better color fidelity, lower noise, and higher reflectance stability.
CMAWRNet: Multiple Adverse Weather Removal via a Unified Quaternion Neural Architecture
May 03, 2025



Images used in real-world applications such as image or video retrieval, outdoor surveillance, and autonomous driving suffer from poor weather conditions. When designing robust computer vision systems, removing adverse weather such as haze, rain, and snow is a significant problem. Recently, deep-learning methods offered a solution for a single type of degradation. Current state-of-the-art universal methods struggle with combinations of degradations, such as haze and rain-streak. Few algorithms have been developed that perform well when presented with images containing multiple adverse weather conditions. This work focuses on developing an efficient solution for multiple adverse weather removal using a unified quaternion neural architecture called CMAWRNet. It is based on a novel texture-structure decomposition block, a novel lightweight encoder-decoder quaternion transformer architecture, and an attentive fusion block with low-light correction. We also introduce a quaternion similarity loss function to preserve color information better. The quantitative and qualitative evaluation of the current state-of-the-art benchmarking datasets and real-world images shows the performance advantages of the proposed CMAWRNet compared to other state-of-the-art weather removal approaches dealing with multiple weather artifacts. Extensive computer simulations validate that CMAWRNet improves the performance of downstream applications such as object detection. This is the first time the decomposition approach has been applied to the universal weather removal task.
QSAM-Net: Rain streak removal by quaternion neural network with self-attention module
Aug 08, 2022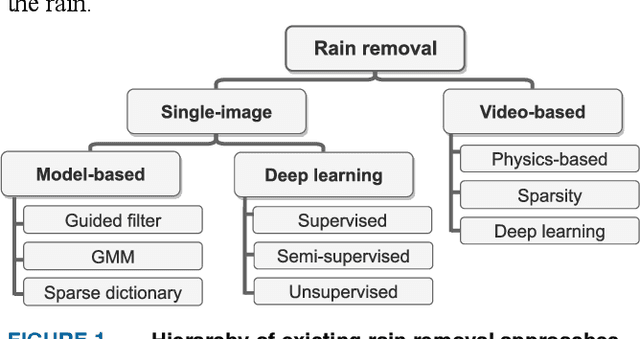
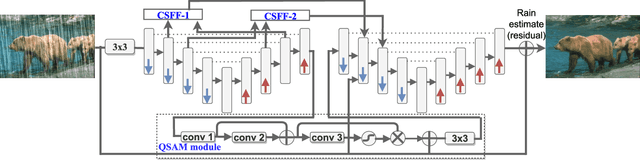


Images captured in real-world applications in remote sensing, image or video retrieval, and outdoor surveillance suffer degraded quality introduced by poor weather conditions. Conditions such as rain and mist, introduce artifacts that make visual analysis challenging and limit the performance of high-level computer vision methods. For time-critical applications where a rapid response is necessary, it becomes crucial to develop algorithms that automatically remove rain, without diminishing the quality of the image contents. This article aims to develop a novel quaternion multi-stage multiscale neural network with a self-attention module called QSAM-Net to remove rain streaks. The novelty of this algorithm is that it requires significantly fewer parameters by a factor of 3.98, over prior methods, while improving visual quality. This is demonstrated by the extensive evaluation and benchmarking on synthetic and real-world rainy images. This feature of QSAM-Net makes the network suitable for implementation on edge devices and applications requiring near real-time performance. The experiments demonstrate that by improving the visual quality of images. In addition, object detection accuracy and training speed are also improved.