 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Performance of an Explainable Language Model on PubMedQA
Apr 07, 2025Large language models (LLMs) have shown significant abilities in retrieving medical knowledge, reasoning over it and answering medical questions comparably to physicians. However, these models are not interpretable, hallucinate, are difficult to maintain and require enormous compute resources for training and inference. In this paper, we report results from Gyan, an explainable language model based on an alternative architecture, on the PubmedQA data set. The Gyan LLM is a compositional language model and the model is decoupled from knowledge. Gyan is trustable, transparent, does not hallucinate and does not require significant training or compute resources. Gyan is easily transferable across domains. Gyan-4.3 achieves SOTA results on PubmedQA with 87.1% accuracy compared to 82% by MedPrompt based on GPT-4 and 81.8% by Med-PaLM 2 (Google and DeepMind). We will be reporting results for other medical data sets - MedQA, MedMCQA, MMLU - Medicine in the future.
Improving Part-of-Speech Tagging for NLP Pipelines
Aug 01, 2017
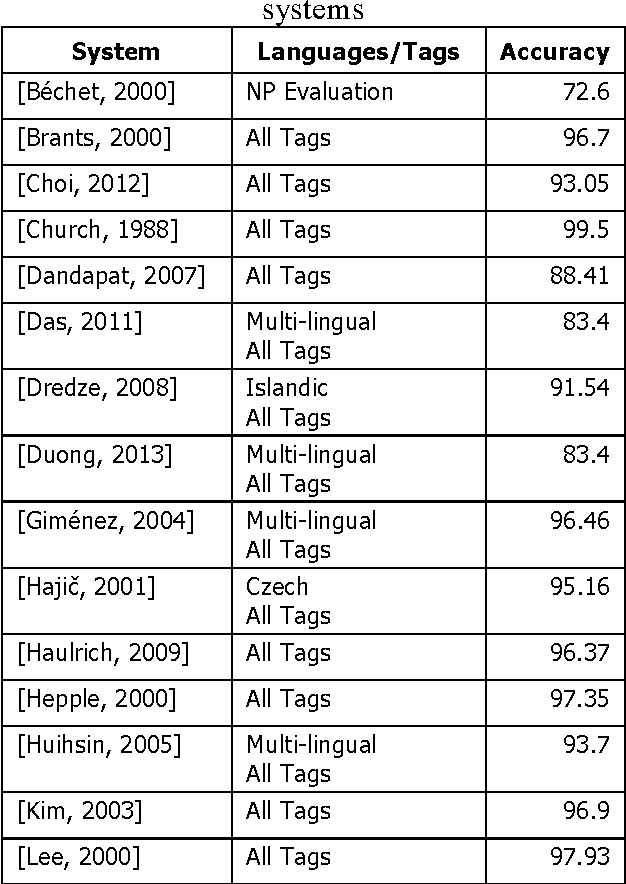
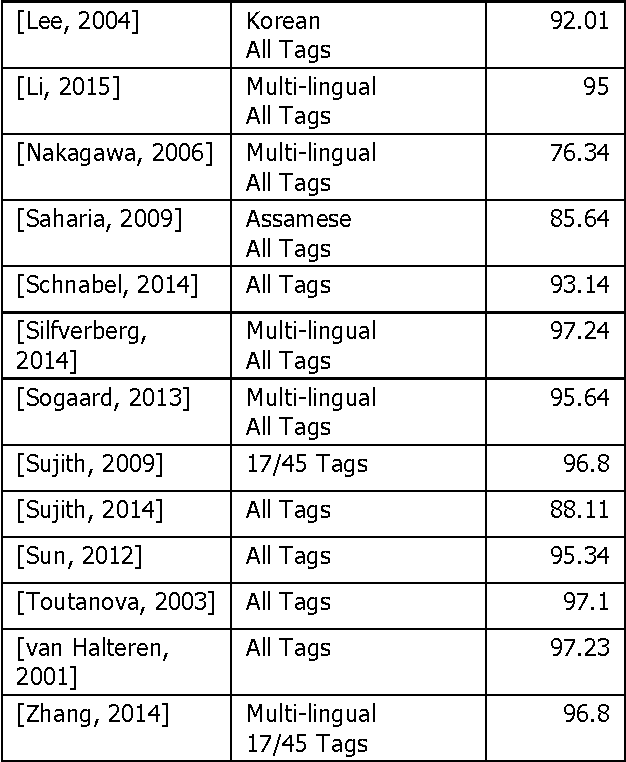

This paper outlines the results of sentence level linguistics based rules for improving part-of-speech tagging. It is well known that the performance of complex NLP systems is negatively affected if one of the preliminary stages is less than perfect. Errors in the initial stages in the pipeline have a snowballing effect on the pipeline's end performance. We have created a set of linguistics based rules at the sentence level which adjust part-of-speech tags from state-of-the-art taggers. Comparison with state-of-the-art taggers on widely used benchmarks demonstrate significant improvements in tagging accuracy and consequently in the quality and accuracy of NLP systems.