 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Rank Graph-based Application Objects on Heterogeneous Memories
Nov 04, 2022Persistent Memory (PMEM), also known as Non-Volatile Memory (NVM), can deliver higher density and lower cost per bit when compared with DRAM. Its main drawback is that it is typically slower than DRAM. On the other hand, DRAM has scalability problems due to its cost and energy consumption. Soon, PMEM will likely coexist with DRAM in computer systems but the biggest challenge is to know which data to allocate on each type of memory. This paper describes a methodology for identifying and characterizing application objects that have the most influence on the application's performance using Intel Optane DC Persistent Memory. In the first part of our work, we built a tool that automates the profiling and analysis of application objects. In the second part, we build a machine learning model to predict the most critical object within large-scale graph-based applications. Our results show that using isolated features does not bring the same benefit compared to using a carefully chosen set of features. By performing data placement using our predictive model, we can reduce the execution time degradation by 12\% (average) and 30\% (max) when compared to the baseline's approach based on LLC misses indicator.
Intelligent colocation of HPC workloads
Mar 16, 2021
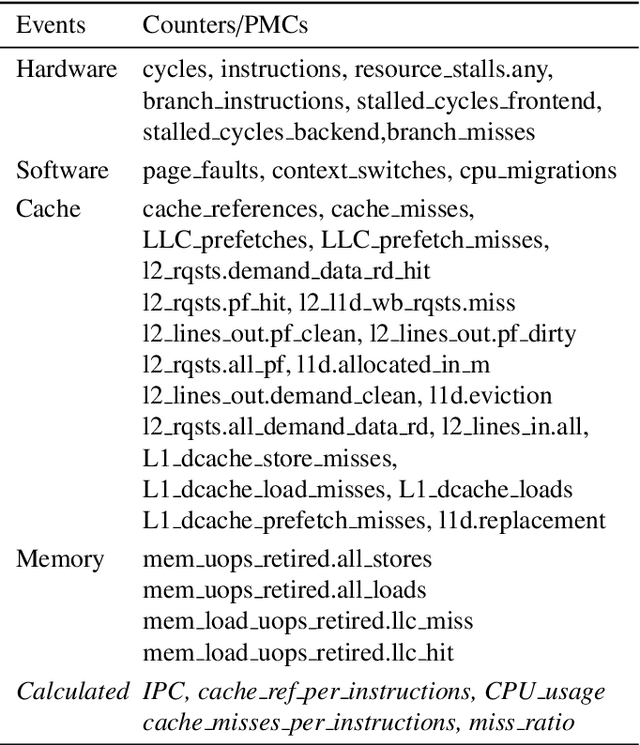


Many HPC applications suffer from a bottleneck in the shared caches, instruction execution units, I/O or memory bandwidth, even though the remaining resources may be underutilized. It is hard for developers and runtime systems to ensure that all critical resources are fully exploited by a single application, so an attractive technique for increasing HPC system utilization is to colocate multiple applications on the same server. When applications share critical resources, however, contention on shared resources may lead to reduced application performance. In this paper, we show that server efficiency can be improved by first modeling the expected performance degradation of colocated applications based on measured hardware performance counters, and then exploiting the model to determine an optimized mix of colocated applications. This paper presents a new intelligent resource manager and makes the following contributions: (1) a new machine learning model to predict the performance degradation of colocated applications based on hardware counters and (2) an intelligent scheduling scheme deployed on an existing resource manager to enable application co-scheduling with minimum performance degradation. Our results show that our approach achieves performance improvements of 7% (avg) and 12% (max) compared to the standard policy commonly used by existing job managers.
* Submitted to Journal of Parallel and Distributed Computing