 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcrastination Is All You Need: Exponent Indexed Accumulators for Floating Point, Posits and Logarithmic Numbers
Jun 09, 2024This paper discusses a simple and effective method for the summation of long sequences of floating point numbers. The method comprises two phases: an accumulation phase where the mantissas of the floating point numbers are added to accumulators indexed by the exponents and a reconstruction phase where the actual summation result is finalised. Various architectural details are given for both FPGAs and ASICs including fusing the operation with a multiplier, creating efficient MACs. Some results are presented for FPGAs, including a tensor core capable of multiplying and accumulating two 4x4 matrices of bfloat16 values every clock cycle using ~6,400 LUTs + 64 DSP48 in AMD FPGAs at 700+ MHz. The method is then extended to posits and logarithmic numbers.
From a Lossless (~1.5:1) Compression Algorithm for Llama2 7B Weights to Variable Precision, Variable Range, Compressed Numeric Data Types for CNNs and LLMs
Apr 16, 2024This paper starts with a simple lossless ~1.5:1 compression algorithm for the weights of the Large Language Model (LLM) Llama2 7B [1] that can be implemented in ~200 LUTs in AMD FPGAs, processing over 800 million bfloat16 numbers per second. This framework is then extended to variable precision, variable range, compressed numerical data types that are a user defined super set of both floats and posits [2]. The paper then discusses a simple hardware implementation of such format based on ANS (Asymmetrical Numeral Systems) [3] that acts as a bridge between this flexible data format and a computational engine while, at the same time, achieving bandwidth reduction. An example of a token factory using weight compression and sharing is also given.
A MAC-less Neural Inference Processor Supporting Compressed, Variable Precision Weights
Dec 10, 2020



This paper introduces two architectures for the inference of convolutional neural networks (CNNs). Both architectures exploit weight sparsity and compression to reduce computational complexity and bandwidth. The first architecture uses multiply-accumulators (MACs) but avoids unnecessary multiplications by skipping zero weights. The second architecture exploits weight sparsity at the level of their bit representation by substituting resource-intensive MACs with much smaller Bit Layer Multiply Accumulators (BLMACs). The use of BLMACs also allows variable precision weights as variable size integers and even floating points. Some details of an implementation of the second architecture are given. Weight compression with arithmetic coding is also discussed as well as bandwidth implications. Finally, some implementation results for a pathfinder design and various technologies are presented.
Pyramid Vector Quantization and Bit Level Sparsity in Weights for Efficient Neural Networks Inference
Nov 24, 2019



This paper discusses three basic blocks for the inference of convolutional neural networks (CNNs). Pyramid Vector Quantization (PVQ) is discussed as an effective quantizer for CNNs weights resulting in highly sparse and compressible networks. Properties of PVQ are exploited for the elimination of multipliers during inference while maintaining high performance. The result is then extended to any other quantized weights. The Tiny Yolo v3 CNN is used to compare such basic blocks.
Pyramid Vector Quantization for Deep Learning
Apr 10, 2017

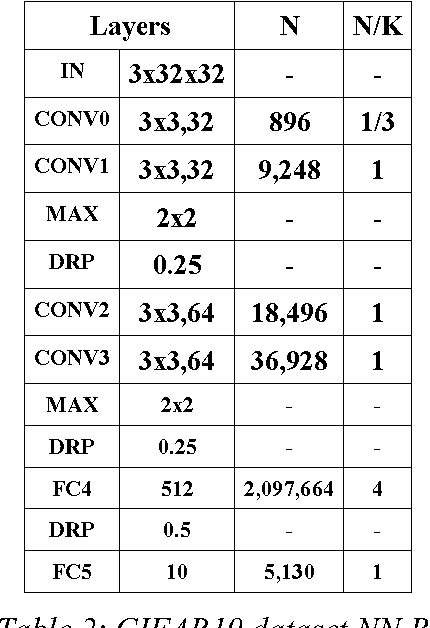

This paper explores the use of Pyramid Vector Quantization (PVQ) to reduce the computational cost for a variety of neural networks (NNs) while, at the same time, compressing the weights that describe them. This is based on the fact that the dot product between an N dimensional vector of real numbers and an N dimensional PVQ vector can be calculated with only additions and subtractions and one multiplication. This is advantageous since tensor products, commonly used in NNs, can be re-conduced to a dot product or a set of dot products. Finally, it is stressed that any NN architecture that is based on an operation that can be re-conduced to a dot product can benefit from the techniques described here.
Vector Quantization for Machine Vision
Mar 30, 2016
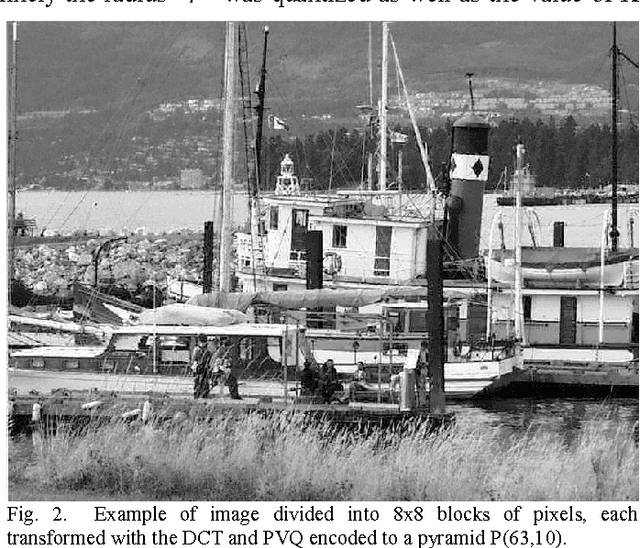


This paper shows how to reduce the computational cost for a variety of common machine vision tasks by operating directly in the compressed domain, particularly in the context of hardware acceleration. Pyramid Vector Quantization (PVQ) is the compression technique of choice and its properties are exploited to simplify Support Vector Machines (SVM), Convolutional Neural Networks(CNNs), Histogram of Oriented Gradients (HOG) features, interest points matching and other algorithms.