 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing instance hardness in classification and regression problems
Dec 04, 2022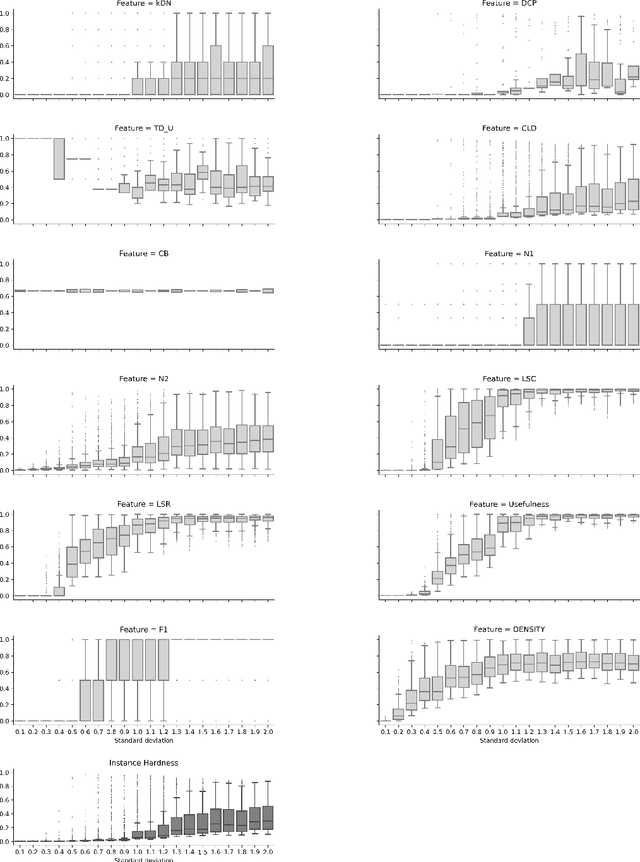
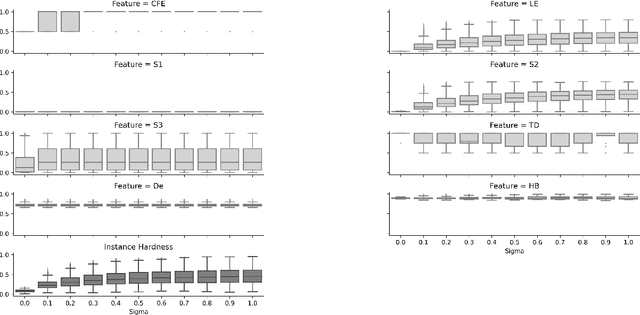
Some recent pieces of work in the Machine Learning (ML) literature have demonstrated the usefulness of assessing which observations are hardest to have their label predicted accurately. By identifying such instances, one may inspect whether they have any quality issues that should be addressed. Learning strategies based on the difficulty level of the observations can also be devised. This paper presents a set of meta-features that aim at characterizing which instances of a dataset are hardest to have their label predicted accurately and why they are so, aka instance hardness measures. Both classification and regression problems are considered. Synthetic datasets with different levels of complexity are built and analyzed. A Python package containing all implementations is also provided.