 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative study of Transformer and LSTM Network with attention mechanism on Image Captioning
Mar 05, 2023In a globalized world at the present epoch of generative intelligence, most of the manual labour tasks are automated with increased efficiency. This can support businesses to save time and money. A crucial component of generative intelligence is the integration of vision and language. Consequently, image captioning become an intriguing area of research. There have been multiple attempts by the researchers to solve this problem with different deep learning architectures, although the accuracy has increased, but the results are still not up to standard. This study buckles down to the comparison of Transformer and LSTM with attention block model on MS-COCO dataset, which is a standard dataset for image captioning. For both the models we have used pretrained Inception-V3 CNN encoder for feature extraction of the images. The Bilingual Evaluation Understudy score (BLEU) is used to checked the accuracy of caption generated by both models. Along with the transformer and LSTM with attention block models,CLIP-diffusion model, M2-Transformer model and the X-Linear Attention model have been discussed with state of the art accuracy.
A Comparison of Audio Preprocessing Techniques and Deep Learning Algorithms for Raga Recognition
Dec 10, 2022

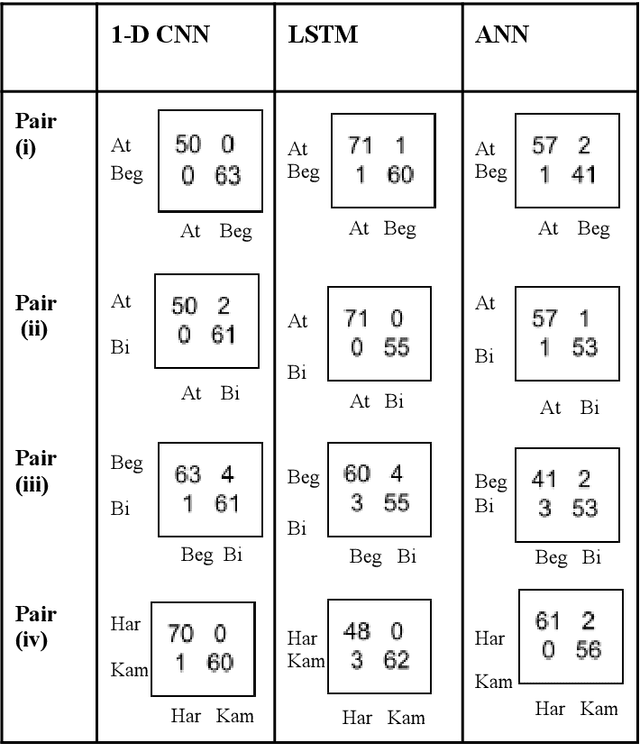

Ragas form the foundation for Indian Classical Music. The task of Raga Recognition has gained traction in the Music Information Retrieval community in the recent past, which can be attributed to the nuances of Indian Classical Music that have resulted in a plethora of research problems in Computing. In this work, we used two different digital audio signal processing techniques to preprocess audio samples of Carnatic classical ragas that were then processed by various Deep Learning models. Their results were compared in order to infer which DASP technique is better suited to the task of raga recognition. We obtained state of the art results, with our best model reaching a testing accuracy of 98.1%. We also compared each model ability to distinguish between similar ragas.