 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Passenger Detection with Smartphone/Bus Implicit Interaction and Multisensory Unsupervised Cause-effect Learning
Feb 24, 2022
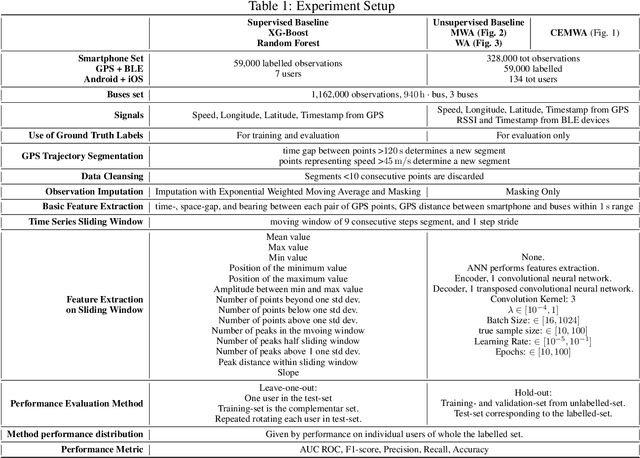
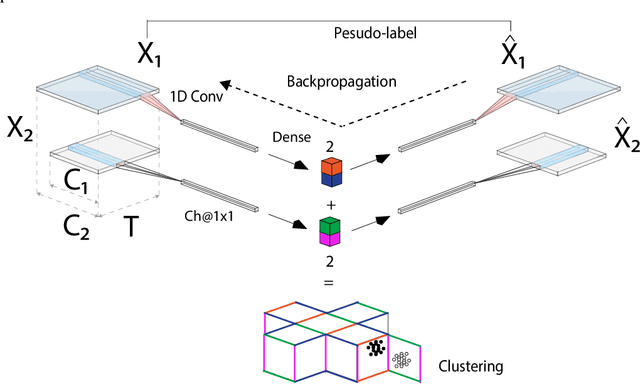

Intelligent Transportation Systems (ITS) underpin the concept of Mobility as a Service (MaaS), which requires universal and seamless users' access across multiple public and private transportation systems while allowing operators' proportional revenue sharing. Current user sensing technologies such as Walk-in/Walk-out (WIWO) and Check-in/Check-out (CICO) have limited scalability for large-scale deployments. These limitations prevent ITS from supporting analysis, optimization, calculation of revenue sharing, and control of MaaS comfort, safety, and efficiency. We focus on the concept of implicit Be-in/Be-out (BIBO) smartphone-sensing and classification. To close the gap and enhance smartphones towards MaaS, we developed a proprietary smartphone-sensing platform collecting contemporary Bluetooth Low Energy (BLE) signals from BLE devices installed on buses and Global Positioning System (GPS) locations of both buses and smartphones. To enable the training of a model based on GPS features against the BLE pseudo-label, we propose the Cause-Effect Multitask Wasserstein Autoencoder (CEMWA). CEMWA combines and extends several frameworks around Wasserstein autoencoders and neural networks. As a dimensionality reduction tool, CEMWA obtains an auto-validated representation of a latent space describing users' smartphones within the transport system. This representation allows BIBO clustering via DBSCAN. We perform an ablation study of CEMWA's alternative architectures and benchmark against the best available supervised methods. We analyze performance's sensitivity to label quality. Under the na\"ive assumption of accurate ground truth, XGBoost outperforms CEMWA. Although XGBoost and Random Forest prove to be tolerant to label noise, CEMWA is agnostic to label noise by design and provides the best performance with an 88\% F1 score.
Mining User Behaviour from Smartphone data: a literature review
Feb 03, 2020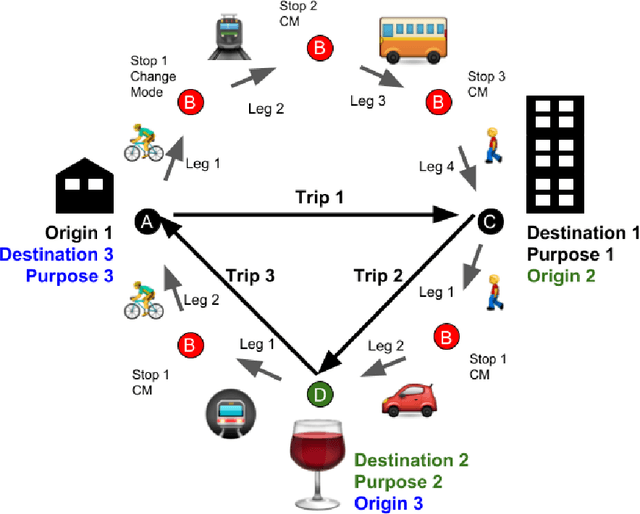
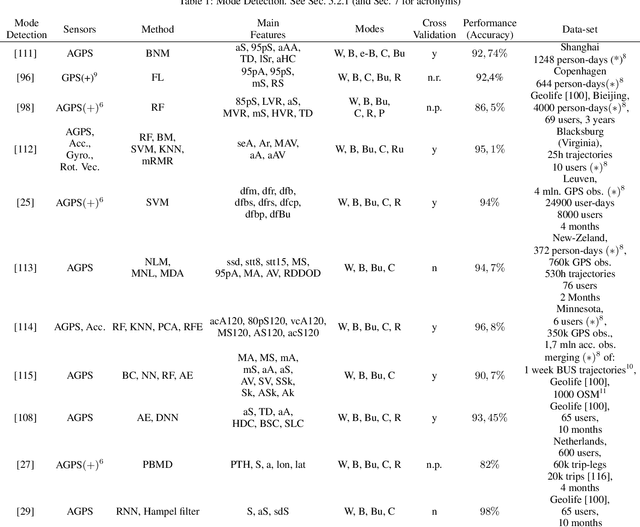
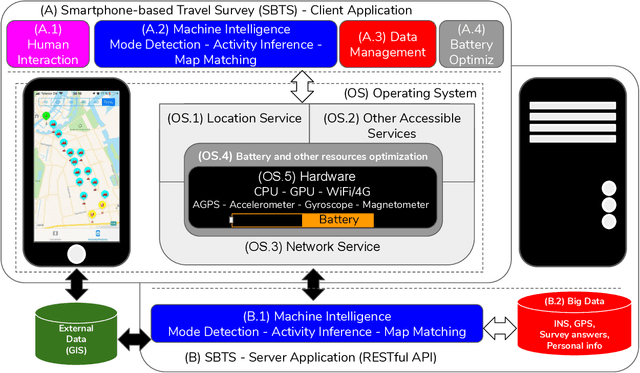
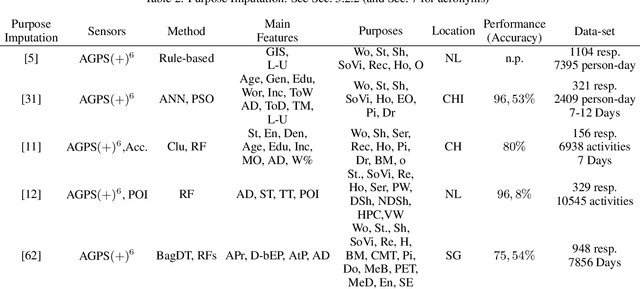
To study users' travel behaviour and travel time between origin and destination, researchers employ travel surveys. Although there is consensus in the field about the potential, after over ten years of research and field experimentation, Smartphone-based travel surveys still did not take off to a large scale. Here, computer intelligence algorithms take the role that operators have in Traditional Travel Surveys; since we train each algorithm on data, performances rest on the data quality, thus on the ground truth. Inaccurate validations affect negatively: labels, algorithms' training, travel diaries precision, and therefore data validation, within a very critical loop. Interestingly, boundaries are proven burdensome to push even for Machine Learning methods. To support optimal investment decisions for practitioners, we expose the drivers they should consider when assessing what they need against what they get. This paper highlights and examines the critical aspects of the underlying research and provides some recommendations: (i) from the device perspective, on the main physical limitations; (ii) from the application perspective, the methodological framework deployed for the automatic generation of travel diaries; (iii)from the ground truth perspective, the relationship between user interaction, methods, and data.