 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Generalization in Polyp Segmentation with DINO Self-Attention "keys"
Dec 15, 2025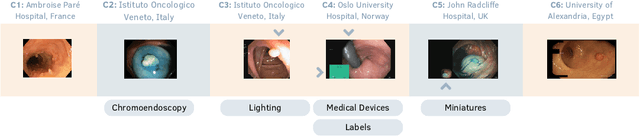

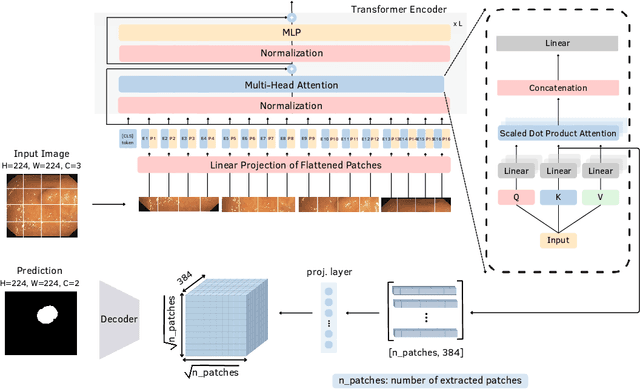

Automatic polyp segmentation is crucial for improving the clinical identification of colorectal cancer (CRC). While Deep Learning (DL) techniques have been extensively researched for this problem, current methods frequently struggle with generalization, particularly in data-constrained or challenging settings. Moreover, many existing polyp segmentation methods rely on complex, task-specific architectures. To address these limitations, we present a framework that leverages the intrinsic robustness of DINO self-attention "key" features for robust segmentation. Unlike traditional methods that extract tokens from the deepest layers of the Vision Transformer (ViT), our approach leverages the key features of the self-attention module with a simple convolutional decoder to predict polyp masks, resulting in enhanced performance and better generalizability. We validate our approach using a multi-center dataset under two rigorous protocols: Domain Generalization (DG) and Extreme Single Domain Generalization (ESDG). Our results, supported by a comprehensive statistical analysis, demonstrate that this pipeline achieves state-of-the-art (SOTA) performance, significantly enhancing generalization, particularly in data-scarce and challenging scenarios. While avoiding a polyp-specific architecture, we surpass well-established models like nnU-Net and UM-Net. Additionally, we provide a systematic benchmark of the DINO framework's evolution, quantifying the specific impact of architectural advancements on downstream polyp segmentation performance.
FedGS: Federated Gradient Scaling for Heterogeneous Medical Image Segmentation
Aug 21, 2024Federated Learning (FL) in Deep Learning (DL)-automated medical image segmentation helps preserving privacy by enabling collaborative model training without sharing patient data. However, FL faces challenges with data heterogeneity among institutions, leading to suboptimal global models. Integrating Disentangled Representation Learning (DRL) in FL can enhance robustness by separating data into distinct representations. Existing DRL methods assume heterogeneity lies solely in style features, overlooking content-based variability like lesion size and shape. We propose FedGS, a novel FL aggregation method, to improve segmentation performance on small, under-represented targets while maintaining overall efficacy. FedGS demonstrates superior performance over FedAvg, particularly for small lesions, across PolypGen and LiTS datasets. The code and pre-trained checkpoints are available at the following link: https://github.com/Trustworthy-AI-UU-NKI/Federated-Learning-Disentanglement
Enhancing Cross-Modal Medical Image Segmentation through Compositionality
Aug 21, 2024Cross-modal medical image segmentation presents a significant challenge, as different imaging modalities produce images with varying resolutions, contrasts, and appearances of anatomical structures. We introduce compositionality as an inductive bias in a cross-modal segmentation network to improve segmentation performance and interpretability while reducing complexity. The proposed network is an end-to-end cross-modal segmentation framework that enforces compositionality on the learned representations using learnable von Mises-Fisher kernels. These kernels facilitate content-style disentanglement in the learned representations, resulting in compositional content representations that are inherently interpretable and effectively disentangle different anatomical structures. The experimental results demonstrate enhanced segmentation performance and reduced computational costs on multiple medical datasets. Additionally, we demonstrate the interpretability of the learned compositional features. Code and checkpoints will be publicly available at: https://github.com/Trustworthy-AI-UU-NKI/Cross-Modal-Segmentation.
Interpretability-guided Data Augmentation for Robust Segmentation in Multi-centre Colonoscopy Data
Aug 30, 2023Multi-centre colonoscopy images from various medical centres exhibit distinct complicating factors and overlays that impact the image content, contingent on the specific acquisition centre. Existing Deep Segmentation networks struggle to achieve adequate generalizability in such data sets, and the currently available data augmentation methods do not effectively address these sources of data variability. As a solution, we introduce an innovative data augmentation approach centred on interpretability saliency maps, aimed at enhancing the generalizability of Deep Learning models within the realm of multi-centre colonoscopy image segmentation. The proposed augmentation technique demonstrates increased robustness across different segmentation models and domains. Thorough testing on a publicly available multi-centre dataset for polyp detection demonstrates the effectiveness and versatility of our approach, which is observed both in quantitative and qualitative results. The code is publicly available at: https://github.com/nki-radiology/interpretability_augmentation