 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Frequency Modulation: Training-Free Spectral Modulation of Diffusion Cross-Attention
Mar 30, 2026Cross-attention is the primary interface through which text conditions latent diffusion models, yet its step-wise multi-resolution dynamics remain under-characterized, limiting principled training-free control. We cast diffusion cross-attention as a spatiotemporal signal on the latent grid by summarizing token-softmax weights into token-agnostic concentration maps and tracking their radially binned Fourier power over denoising. Across prompts and seeds, encoder cross-attention exhibits a consistent coarse-to-fine spectral progression, yielding a stable time-frequency fingerprint of token competition. Building on this structure, we introduce Attention Frequency Modulation (AFM), a plug-and-play inference-time intervention that edits token-wise pre-softmax cross-attention logits in the Fourier domain: low- and high-frequency bands are reweighted with a progress-aligned schedule and can be adaptively gated by token-allocation entropy, before the token softmax. AFM provides a continuous handle to bias the spatial scale of token-competition patterns without retraining, prompt editing, or parameter updates. Experiments on Stable Diffusion show that AFM reliably redistributes attention spectra and produces substantial visual edits while largely preserving semantic alignment. Finally, we find that entropy mainly acts as an adaptive gain on the same frequency-based edit rather than an independent control axis.
Facial Expression-Enhanced TTS: Combining Face Representation and Emotion Intensity for Adaptive Speech
Sep 24, 2024We propose FEIM-TTS, an innovative zero-shot text-to-speech (TTS) model that synthesizes emotionally expressive speech, aligned with facial images and modulated by emotion intensity. Leveraging deep learning, FEIM-TTS transcends traditional TTS systems by interpreting facial cues and adjusting to emotional nuances without dependence on labeled datasets. To address sparse audio-visual-emotional data, the model is trained using LRS3, CREMA-D, and MELD datasets, demonstrating its adaptability. FEIM-TTS's unique capability to produce high-quality, speaker-agnostic speech makes it suitable for creating adaptable voices for virtual characters. Moreover, FEIM-TTS significantly enhances accessibility for individuals with visual impairments or those who have trouble seeing. By integrating emotional nuances into TTS, our model enables dynamic and engaging auditory experiences for webcomics, allowing visually impaired users to enjoy these narratives more fully. Comprehensive evaluation evidences its proficiency in modulating emotion and intensity, advancing emotional speech synthesis and accessibility. Samples are available at: https://feim-tts.github.io/.
Swish-T : Enhancing Swish Activation with Tanh Bias for Improved Neural Network Performance
Jul 02, 2024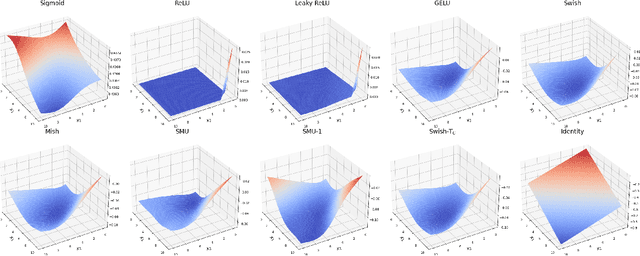
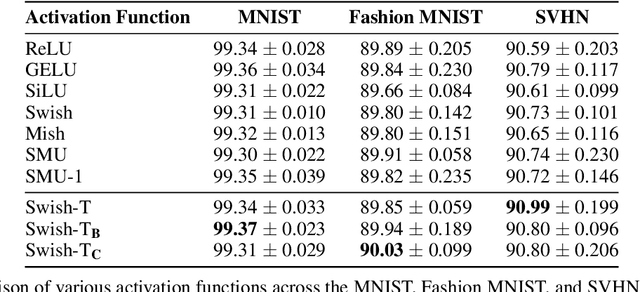
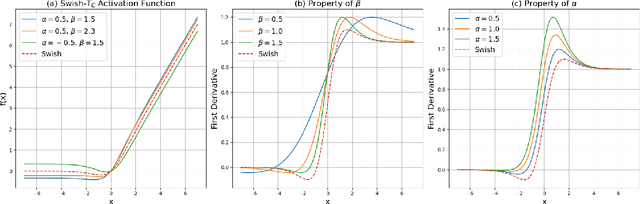
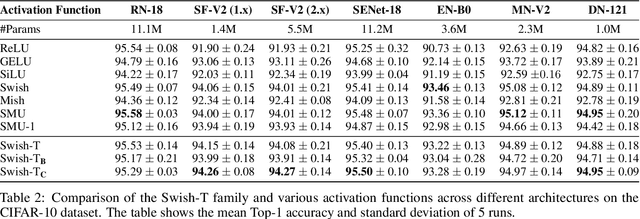
We propose the Swish-T family, an enhancement of the existing non-monotonic activation function Swish. Swish-T is defined by adding a Tanh bias to the original Swish function. This modification creates a family of Swish-T variants, each designed to excel in different tasks, showcasing specific advantages depending on the application context. The Tanh bias allows for broader acceptance of negative values during initial training stages, offering a smoother non-monotonic curve than the original Swish. We ultimately propose the Swish-T$_{\textbf{C}}$ function, while Swish-T and Swish-T$_{\textbf{B}}$, byproducts of Swish-T$_{\textbf{C}}$, also demonstrate satisfactory performance. Furthermore, our ablation study shows that using Swish-T$_{\textbf{C}}$ as a non-parametric function can still achieve high performance. The superiority of the Swish-T family has been empirically demonstrated across various models and benchmark datasets, including MNIST, Fashion MNIST, SVHN, CIFAR-10, and CIFAR-100. The code is publicly available at "https://github.com/ictseoyoungmin/Swish-T-pytorch".