 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLA: Twitter Linguistic Analysis
Jul 20, 2021Linguistics has been instrumental in developing a deeper understanding of human nature. Words are indispensable to bequeath the thoughts, emotions, and purpose of any human interaction, and critically analyzing these words can elucidate the social and psychological behavior and characteristics of these social animals. Social media has become a platform for human interaction on a large scale and thus gives us scope for collecting and using that data for our study. However, this entire process of collecting, labeling, and analyzing this data iteratively makes the entire procedure cumbersome. To make this entire process easier and structured, we would like to introduce TLA(Twitter Linguistic Analysis). In this paper, we describe TLA and provide a basic understanding of the framework and discuss the process of collecting, labeling, and analyzing data from Twitter for a corpus of languages while providing detailed labeled datasets for all the languages and the models are trained on these datasets. The analysis provided by TLA will also go a long way in understanding the sentiments of different linguistic communities and come up with new and innovative solutions for their problems based on the analysis.
XBNet : An Extremely Boosted Neural Network
Jun 14, 2021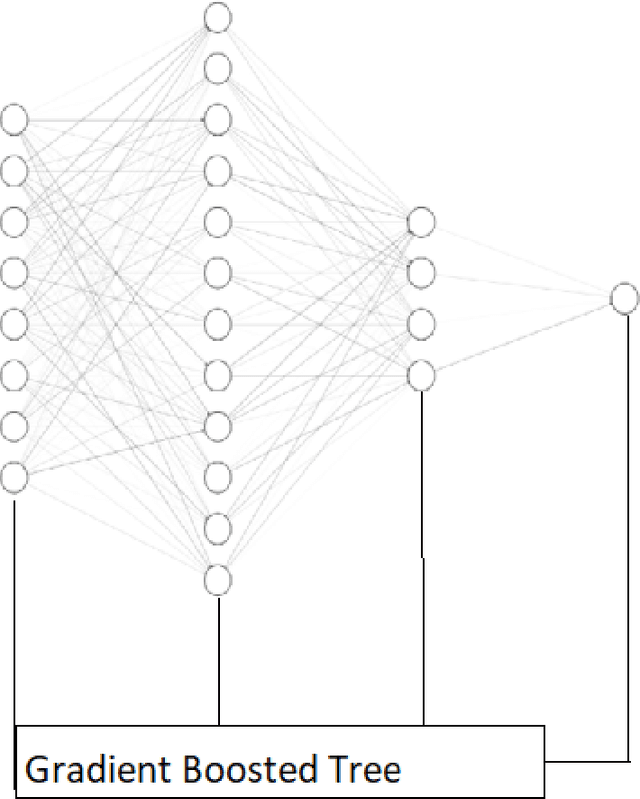
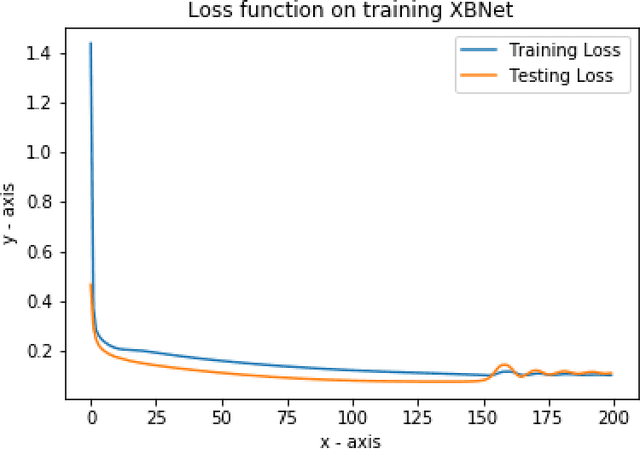
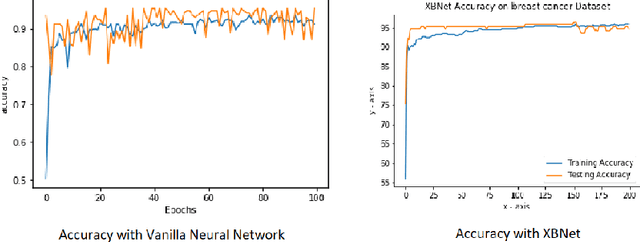
Neural networks have proved to be very robust at processing unstructured data like images, text, videos, and audio. However, it has been observed that their performance is not up to the mark in tabular data; hence tree-based models are preferred in such scenarios. A popular model for tabular data is boosted trees, a highly efficacious and extensively used machine learning method, and it also provides good interpretability compared to neural networks. In this paper, we describe a novel architecture XBNet, which tries to combine tree-based models with that of neural networks to create a robust architecture trained by using a novel optimization technique, Boosted Gradient Descent for Tabular Data which increases its interpretability and performance.
COVID-19 cases prediction using regression and novel SSM model for non-converged countries
Jun 04, 2021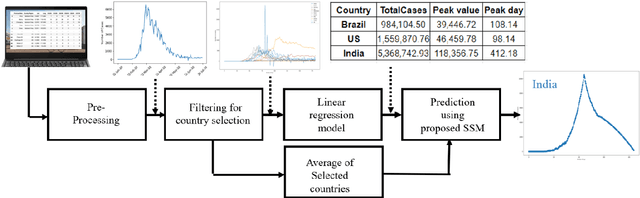
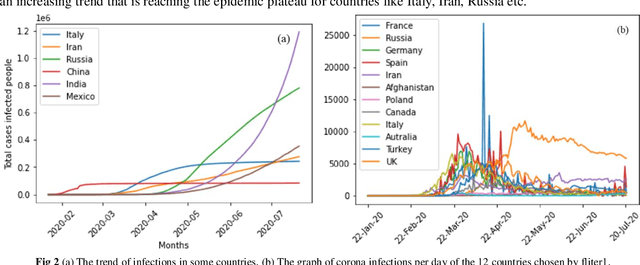
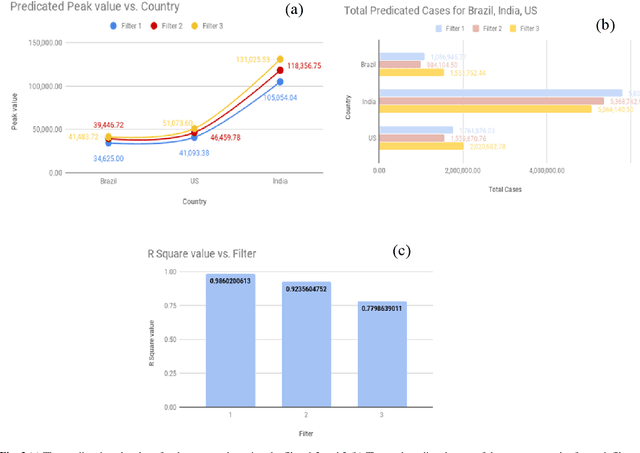
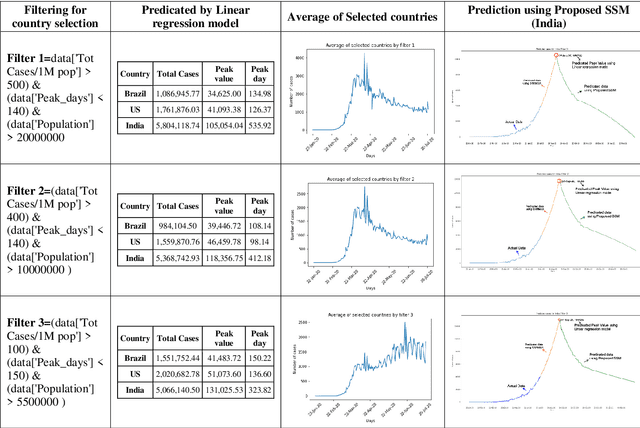
Anticipating the quantity of new associated or affirmed cases with novel coronavirus ailment 2019 (COVID-19) is critical in the counteraction and control of the COVID-19 flare-up. The new associated cases with COVID-19 information were gathered from 20 January 2020 to 21 July 2020. We filtered out the countries which are converging and used those for training the network. We utilized the SARIMAX, Linear regression model to anticipate new suspected COVID-19 cases for the countries which did not converge yet. We predict the curve of non-converged countries with the help of proposed Statistical SARIMAX model (SSM). We present new information investigation-based forecast results that can assist governments with planning their future activities and help clinical administrations to be more ready for what's to come. Our framework can foresee peak corona cases with an R-Squared value of 0.986 utilizing linear regression and fall of this pandemic at various levels for countries like India, US, and Brazil. We found that considering more countries for training degrades the prediction process as constraints vary from nation to nation. Thus, we expect that the outcomes referenced in this work will help individuals to better understand the possibilities of this pandemic.