 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftware Vulnerability Prediction in Low-Resource Languages: An Empirical Study of CodeBERT and ChatGPT
Apr 26, 2024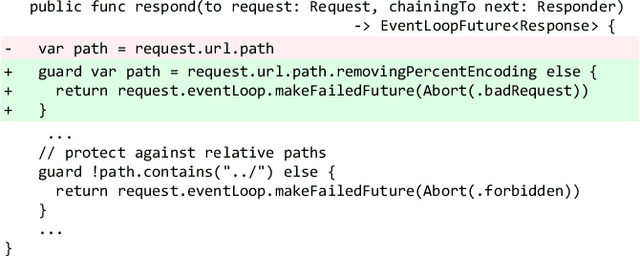
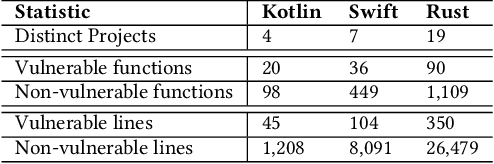

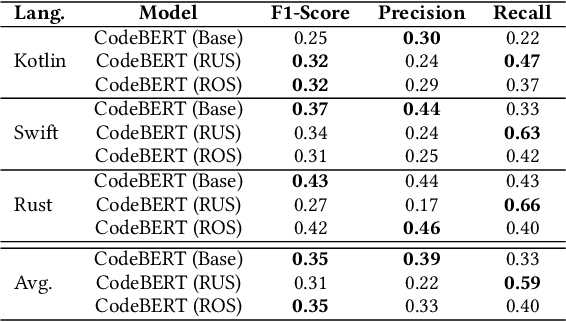
Background: Software Vulnerability (SV) prediction in emerging languages is increasingly important to ensure software security in modern systems. However, these languages usually have limited SV data for developing high-performing prediction models. Aims: We conduct an empirical study to evaluate the impact of SV data scarcity in emerging languages on the state-of-the-art SV prediction model and investigate potential solutions to enhance the performance. Method: We train and test the state-of-the-art model based on CodeBERT with and without data sampling techniques for function-level and line-level SV prediction in three low-resource languages - Kotlin, Swift, and Rust. We also assess the effectiveness of ChatGPT for low-resource SV prediction given its recent success in other domains. Results: Compared to the original work in C/C++ with large data, CodeBERT's performance of function-level and line-level SV prediction significantly declines in low-resource languages, signifying the negative impact of data scarcity. Regarding remediation, data sampling techniques fail to improve CodeBERT; whereas, ChatGPT showcases promising results, substantially enhancing predictive performance by up to 34.4% for the function level and up to 53.5% for the line level. Conclusion: We have highlighted the challenge and made the first promising step for low-resource SV prediction, paving the way for future research in this direction.