 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen Tsetlin Redefining Efficiency in Tsetlin Machine Frameworks
May 07, 2024


Green Tsetlin (GT) is a Tsetlin Machine (TM) framework developed to solve real-world problems using TMs. Several frameworks already exist that provide access to TM implementations. However, these either lack features or have a research-first focus. GT is an easy-to-use framework that aims to lower the complexity and provide a production-ready TM implementation that is great for experienced practitioners and beginners. To this end, GT establishes a clear separation between training and inference. A C++ backend with a Python interface provides competitive training and inference performance, with the option of running in pure Python. It also integrates support for critical components such as exporting trained models, hyper-parameter search, and cross-validation out-of-the-box.
The Sparse Tsetlin Machine: Sparse Representation with Active Literals
May 03, 2024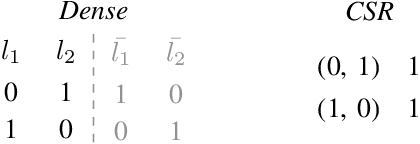



This paper introduces the Sparse Tsetlin Machine (STM), a novel Tsetlin Machine (TM) that processes sparse data efficiently. Traditionally, the TM does not consider data characteristics such as sparsity, commonly seen in NLP applications and other bag-of-word-based representations. Consequently, a TM must initialize, store, and process a significant number of zero values, resulting in excessive memory usage and computational time. Previous attempts at creating a sparse TM have predominantly been unsuccessful, primarily due to their inability to identify which literals are sufficient for TM training. By introducing Active Literals (AL), the STM can focus exclusively on literals that actively contribute to the current data representation, significantly decreasing memory footprint and computational time while demonstrating competitive classification performance.