 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of Conversation Partners from Egocentric Video
Jun 12, 2024


Communicating in noisy, multi-talker environments is challenging, especially for people with hearing impairments. Egocentric video data can potentially be used to identify a user's conversation partners, which could be used to inform selective acoustic amplification of relevant speakers. Recent introduction of datasets and tasks in computer vision enable progress towards analyzing social interactions from an egocentric perspective. Building on this, we focus on the task of identifying conversation partners from egocentric video and describe a suitable dataset. Our dataset comprises 69 hours of egocentric video of diverse multi-conversation scenarios where each individual was assigned one or more conversation partners, providing the labels for our computer vision task. This dataset enables the development and assessment of algorithms for identifying conversation partners and evaluating related approaches. Here, we describe the dataset alongside initial baseline results of this ongoing work, aiming to contribute to the exciting advancements in egocentric video analysis for social settings.
Predicting EEG Responses to Attended Speech via Deep Neural Networks for Speech
Feb 27, 2023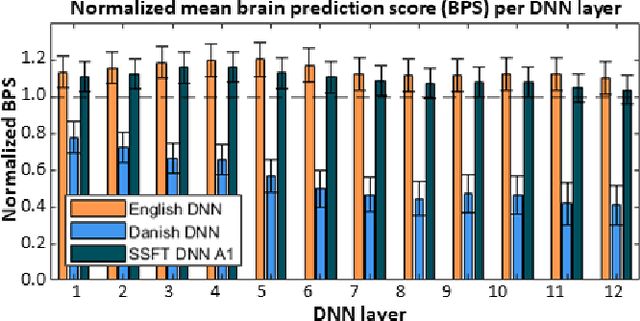
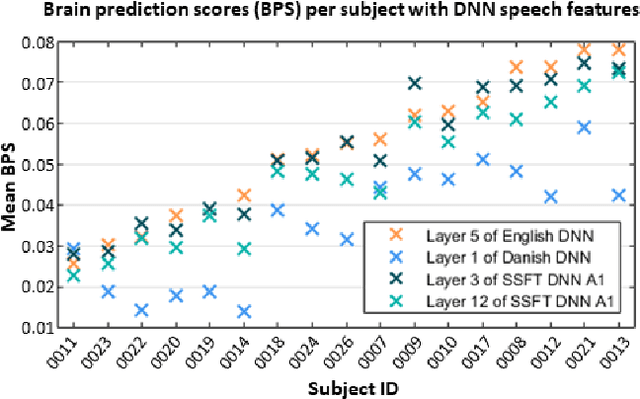
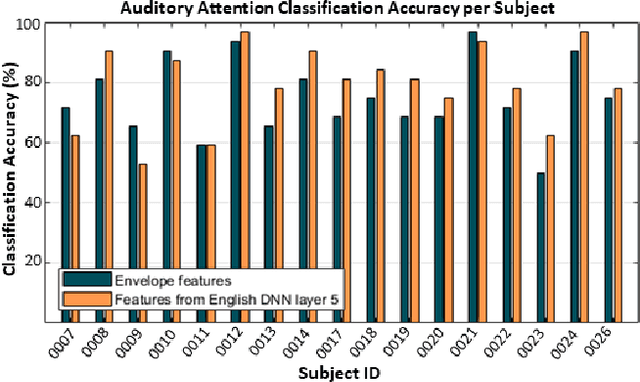
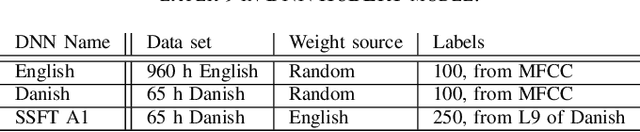
Attending to the speech stream of interest in multi-talker environments can be a challenging task, particularly for listeners with hearing impairment. Research suggests that neural responses assessed with electroencephalography (EEG) are modulated by listener`s auditory attention, revealing selective neural tracking (NT) of the attended speech. NT methods mostly rely on hand-engineered acoustic and linguistic speech features to predict the neural response. Only recently, deep neural network (DNN) models without specific linguistic information have been used to extract speech features for NT, demonstrating that speech features in hierarchical DNN layers can predict neural responses throughout the auditory pathway. In this study, we go one step further to investigate the suitability of similar DNN models for speech to predict neural responses to competing speech observed in EEG. We recorded EEG data using a 64-channel acquisition system from 17 listeners with normal hearing instructed to attend to one of two competing talkers. Our data revealed that EEG responses are significantly better predicted by DNN-extracted speech features than by hand-engineered acoustic features. Furthermore, analysis of hierarchical DNN layers showed that early layers yielded the highest predictions. Moreover, we found a significant increase in auditory attention classification accuracies with the use of DNN-extracted speech features over the use of hand-engineered acoustic features. These findings open a new avenue for development of new NT measures to evaluate and further advance hearing technology.