 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKyrgyzNLP: Challenges, Progress, and Future
Nov 08, 2024

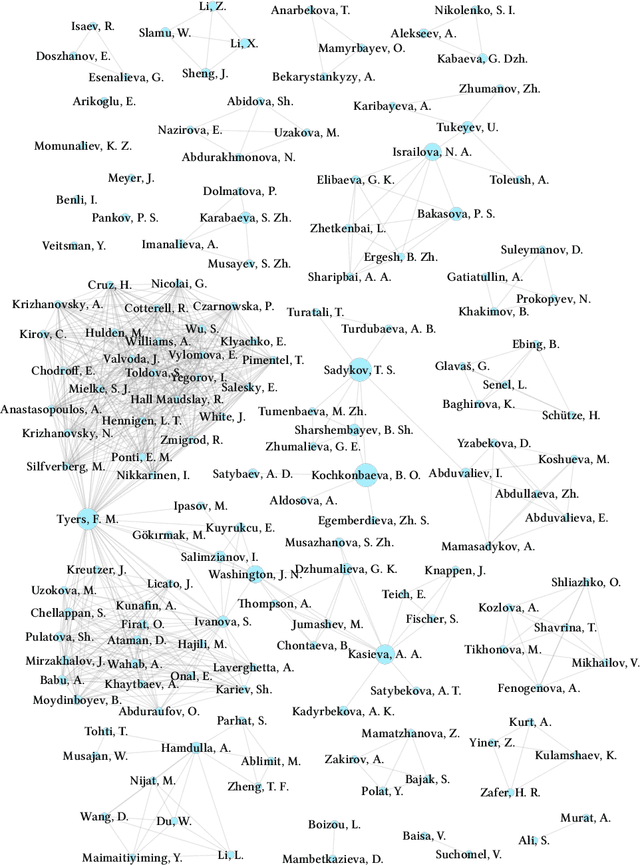
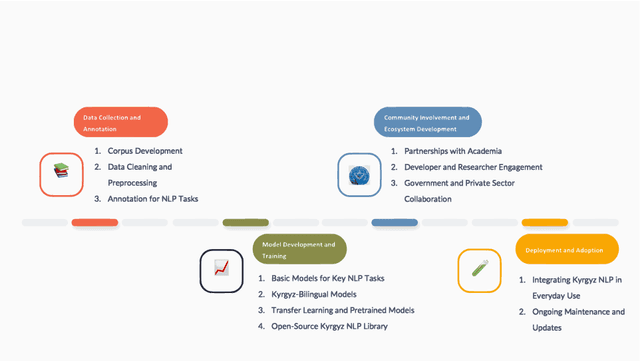
Large language models (LLMs) have excelled in numerous benchmarks, advancing AI applications in both linguistic and non-linguistic tasks. However, this has primarily benefited well-resourced languages, leaving less-resourced ones (LRLs) at a disadvantage. In this paper, we highlight the current state of the NLP field in the specific LRL: kyrgyz tili. Human evaluation, including annotated datasets created by native speakers, remains an irreplaceable component of reliable NLP performance, especially for LRLs where automatic evaluations can fall short. In recent assessments of the resources for Turkic languages, Kyrgyz is labeled with the status 'Scraping By', a severely under-resourced language spoken by millions. This is concerning given the growing importance of the language, not only in Kyrgyzstan but also among diaspora communities where it holds no official status. We review prior efforts in the field, noting that many of the publicly available resources have only recently been developed, with few exceptions beyond dictionaries (the processed data used for the analysis is presented at https://kyrgyznlp.github.io/). While recent papers have made some headway, much more remains to be done. Despite interest and support from both business and government sectors in the Kyrgyz Republic, the situation for Kyrgyz language resources remains challenging. We stress the importance of community-driven efforts to build these resources, ensuring the future advancement sustainability. We then share our view of the most pressing challenges in Kyrgyz NLP. Finally, we propose a roadmap for future development in terms of research topics and language resources.