 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Medical Report Generation for ECG Data: Bridging Medical Text and Signal Processing with Deep Learning
Dec 05, 2024Recent advances in deep learning and natural language generation have significantly improved image captioning, enabling automated, human-like descriptions for visual content. In this work, we apply these captioning techniques to generate clinician-like interpretations of ECG data. This study leverages existing ECG datasets accompanied by free-text reports authored by healthcare professionals (HCPs) as training data. These reports, while often inconsistent, provide a valuable foundation for automated learning. We introduce an encoder-decoder-based method that uses these reports to train models to generate detailed descriptions of ECG episodes. This represents a significant advancement in ECG analysis automation, with potential applications in zero-shot classification and automated clinical decision support. The model is tested on various datasets, including both 1- and 12-lead ECGs. It significantly outperforms the state-of-the-art reference model by Qiu et al., achieving a METEOR score of 55.53% compared to 24.51% achieved by the reference model. Furthermore, several key design choices are discussed, providing a comprehensive overview of current challenges and innovations in this domain. The source codes for this research are publicly available in our Git repository https://git.zib.de/ableich/ecg-comment-generation-public
Bravo MaRDI: A Wikibase Powered Knowledge Graph on Mathematics
Sep 20, 2023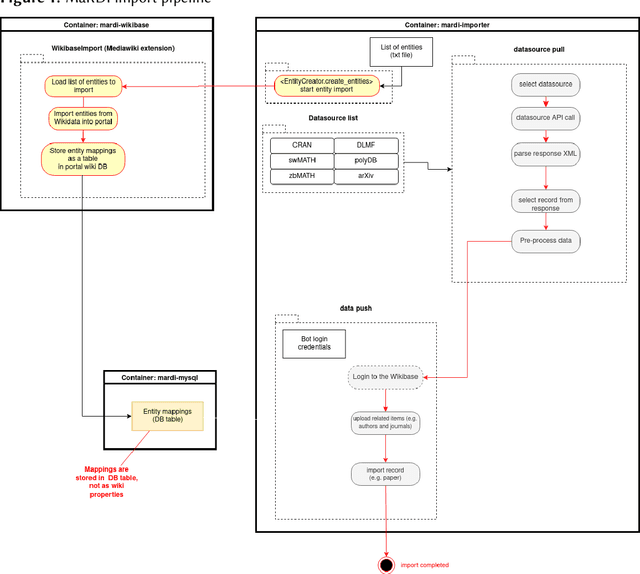
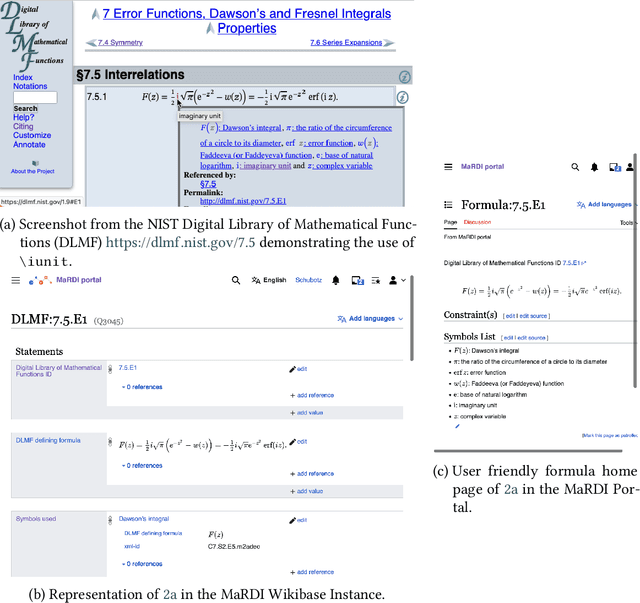
Mathematical world knowledge is a fundamental component of Wikidata. However, to date, no expertly curated knowledge graph has focused specifically on contemporary mathematics. Addressing this gap, the Mathematical Research Data Initiative (MaRDI) has developed a comprehensive knowledge graph that links multimodal research data in mathematics. This encompasses traditional research data items like datasets, software, and publications and includes semantically advanced objects such as mathematical formulas and hypotheses. This paper details the abilities of the MaRDI knowledge graph, which is based on Wikibase, leading up to its inaugural public release, codenamed Bravo, available on https://portal.mardi4nfdi.de.
Enhancing ECG Analysis of Implantable Cardiac Monitor Data: An Efficient Pipeline for Multi-Label Classification
Jul 12, 2023



Implantable Cardiac Monitor (ICM) devices are demonstrating as of today, the fastest-growing market for implantable cardiac devices. As such, they are becoming increasingly common in patients for measuring heart electrical activity. ICMs constantly monitor and record a patient's heart rhythm and when triggered - send it to a secure server where health care professionals (denote HCPs from here on) can review it. These devices employ a relatively simplistic rule-based algorithm (due to energy consumption constraints) to alert for abnormal heart rhythms. This algorithm is usually parameterized to an over-sensitive mode in order to not miss a case (resulting in relatively high false-positive rate) and this, combined with the device's nature of constantly monitoring the heart rhythm and its growing popularity, results in HCPs having to analyze and diagnose an increasingly growing amount of data. In order to reduce the load on the latter, automated methods for ECG analysis are nowadays becoming a great tool to assist HCPs in their analysis. While state-of-the-art algorithms are data-driven rather than rule-based, training data for ICMs often consist of specific characteristics which make its analysis unique and particularly challenging. This study presents the challenges and solutions in automatically analyzing ICM data and introduces a method for its classification that outperforms existing methods on such data. As such, it could be used in numerous ways such as aiding HCPs in the analysis of ECGs originating from ICMs by e.g. suggesting a rhythm type.