 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Models for Media Bias Detection and Subcategorization
Dec 16, 2024We present improved models for the granular detection and sub-classification news media bias in English news articles. We compare the performance of zero-shot versus fine-tuned large pre-trained neural transformer language models, explore how the level of detail of the classes affects performance on a novel taxonomy of 27 news bias-types, and demonstrate how using synthetically generated example data can be used to improve quality
BiasScanner: Automatic Detection and Classification of News Bias to Strengthen Democracy
Jul 15, 2024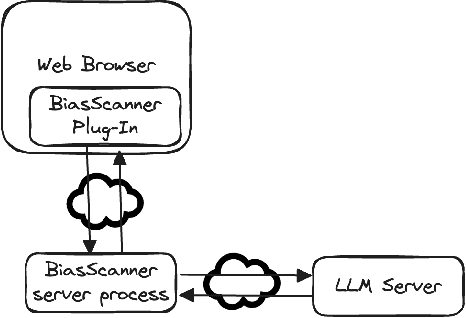
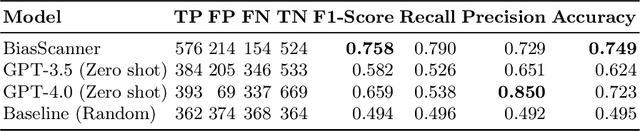


The increasing consumption of news online in the 21st century coincided with increased publication of disinformation, biased reporting, hate speech and other unwanted Web content. We describe BiasScanner, an application that aims to strengthen democracy by supporting news consumers with scrutinizing news articles they are reading online. BiasScanner contains a server-side pre-trained large language model to identify biased sentences of news articles and a front-end Web browser plug-in. At the time of writing, BiasScanner can identify and classify more than two dozen types of media bias at the sentence level, making it the most fine-grained model and only deployed application (automatic system in use) of its kind. It was implemented in a light-weight and privacy-respecting manner, and in addition to highlighting likely biased sentence it also provides explanations for each classification decision as well as a summary analysis for each news article. While prior research has addressed news bias detection, we are not aware of any work that resulted in a deployed browser plug-in (c.f. also biasscanner.org for a Web demo).
Experiments in News Bias Detection with Pre-Trained Neural Transformers
Jun 14, 2024The World Wide Web provides unrivalled access to information globally, including factual news reporting and commentary. However, state actors and commercial players increasingly spread biased (distorted) or fake (non-factual) information to promote their agendas. We compare several large, pre-trained language models on the task of sentence-level news bias detection and sub-type classification, providing quantitative and qualitative results.
Which Country Is This? Automatic Country Ranking of Street View Photos
Jun 11, 2024In this demonstration, we present Country Guesser, a live system that guesses the country that a photo is taken in. In particular, given a Google Street View image, our federated ranking model uses a combination of computer vision, machine learning and text retrieval methods to compute a ranking of likely countries of the location shown in a given image from Street View. Interestingly, using text-based features to probe large pre-trained language models can assist to provide cross-modal supervision. We are not aware of previous country guessing systems informed by visual and textual features.