 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Gaussian Parameterization for Direct Atomic Structure Identification in Electron Tomography
Dec 17, 2025Atomic electron tomography (AET) enables the determination of 3D atomic structures by acquiring a sequence of 2D tomographic projection measurements of a particle and then computationally solving for its underlying 3D representation. Classical tomography algorithms solve for an intermediate volumetric representation that is post-processed into the atomic structure of interest. In this paper, we reformulate the tomographic inverse problem to solve directly for the locations and properties of individual atoms. We parameterize an atomic structure as a collection of Gaussians, whose positions and properties are learnable. This representation imparts a strong physical prior on the learned structure, which we show yields improved robustness to real-world imaging artifacts. Simulated experiments and a proof-of-concept result on experimentally-acquired data confirm our method's potential for practical applications in materials characterization and analysis with Transmission Electron Microscopy (TEM). Our code is available at https://github.com/nalinimsingh/gaussian-atoms.
Universal evaluation and design of imaging systems using information estimation
May 31, 2024



Information theory, which describes the transmission of signals in the presence of noise, has enabled the development of reliable communication systems that underlie the modern world. Imaging systems can also be viewed as a form of communication, in which information about the object is "transmitted" through images. However, the application of information theory to imaging systems has been limited by the challenges of accounting for their physical constraints. Here, we introduce a framework that addresses these limitations by modeling the probabilistic relationship between objects and their measurements. Using this framework, we develop a method to estimate information using only a dataset of noisy measurements, without making any assumptions about the image formation process. We demonstrate that these estimates comprehensively quantify measurement quality across a diverse range of imaging systems and applications. Furthermore, we introduce Information-Driven Encoder Analysis Learning (IDEAL), a technique to optimize the design of imaging hardware for maximum information capture. This work provides new insights into the fundamental performance limits of imaging systems and offers powerful new tools for their analysis and design.
Adversarial Analysis of Natural Language Inference Systems
Dec 07, 2019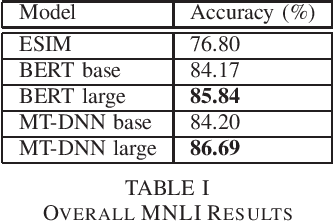
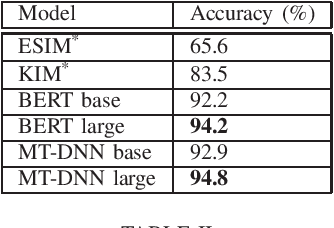
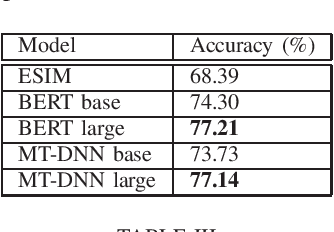
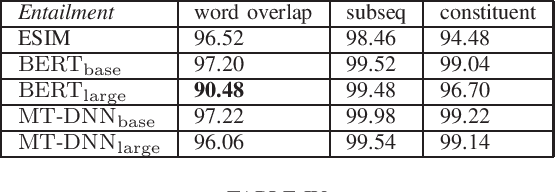
The release of large natural language inference (NLI) datasets like SNLI and MNLI have led to rapid development and improvement of completely neural systems for the task. Most recently, heavily pre-trained, Transformer-based models like BERT and MT-DNN have reached near-human performance on these datasets. However, these standard datasets have been shown to contain many annotation artifacts, allowing models to shortcut understanding using simple fallible heuristics, and still perform well on the test set. So it is no surprise that many adversarial (challenge) datasets have been created that cause models trained on standard datasets to fail dramatically. Although extra training on this data generally improves model performance on just that type of data, transferring that learning to unseen examples is still partial at best. This work evaluates the failures of state-of-the-art models on existing adversarial datasets that test different linguistic phenomena, and find that even though the models perform similarly on MNLI, they differ greatly in their robustness to these attacks. In particular, we find syntax-related attacks to be particularly effective across all models, so we provide a fine-grained analysis and comparison of model performance on those examples. We draw conclusions about the value of model size and multi-task learning (beyond comparing their standard test set performance), and provide suggestions for more effective training data.