 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLT4SG@SMM4H24: Tweets Classification for Digital Epidemiology of Childhood Health Outcomes Using Pre-Trained Language Models
Jun 11, 2024This paper presents our approaches for the SMM4H24 Shared Task 5 on the binary classification of English tweets reporting children's medical disorders. Our first approach involves fine-tuning a single RoBERTa-large model, while the second approach entails ensembling the results of three fine-tuned BERTweet-large models. We demonstrate that although both approaches exhibit identical performance on validation data, the BERTweet-large ensemble excels on test data. Our best-performing system achieves an F1-score of 0.938 on test data, outperforming the benchmark classifier by 1.18%.
EmoMent: An Emotion Annotated Mental Health Corpus from two South Asian Countries
Aug 17, 2022

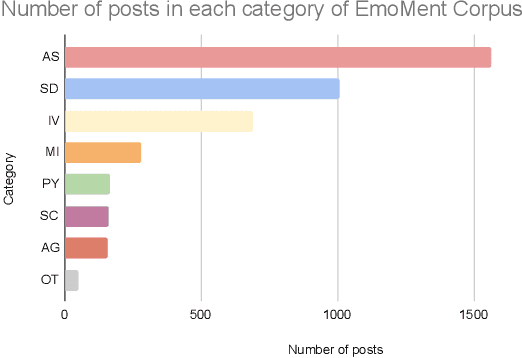

People often utilise online media (e.g., Facebook, Reddit) as a platform to express their psychological distress and seek support. State-of-the-art NLP techniques demonstrate strong potential to automatically detect mental health issues from text. Research suggests that mental health issues are reflected in emotions (e.g., sadness) indicated in a person's choice of language. Therefore, we developed a novel emotion-annotated mental health corpus (EmoMent), consisting of 2802 Facebook posts (14845 sentences) extracted from two South Asian countries - Sri Lanka and India. Three clinical psychology postgraduates were involved in annotating these posts into eight categories, including 'mental illness' (e.g., depression) and emotions (e.g., 'sadness', 'anger'). EmoMent corpus achieved 'very good' inter-annotator agreement of 98.3% (i.e. % with two or more agreement) and Fleiss' Kappa of 0.82. Our RoBERTa based models achieved an F1 score of 0.76 and a macro-averaged F1 score of 0.77 for the first task (i.e. predicting a mental health condition from a post) and the second task (i.e. extent of association of relevant posts with the categories defined in our taxonomy), respectively.
Automated Detection of Cyberbullying Against Women and Immigrants and Cross-domain Adaptability
Dec 04, 2020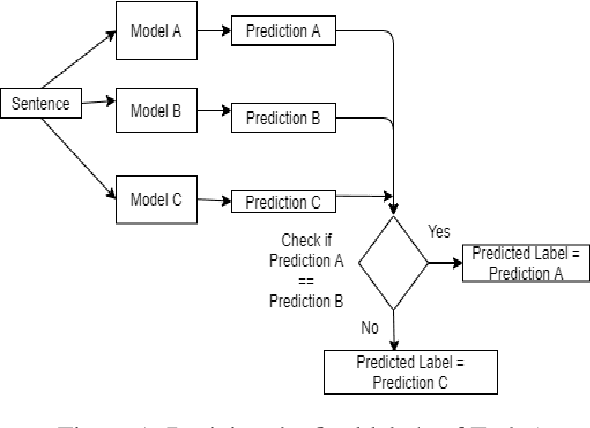


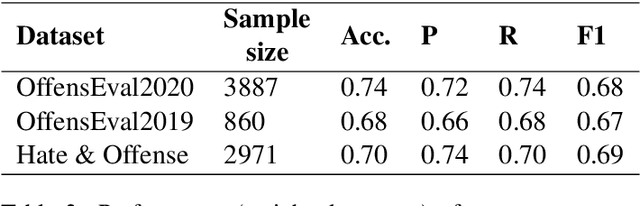
Cyberbullying is a prevalent and growing social problem due to the surge of social media technology usage. Minorities, women, and adolescents are among the common victims of cyberbullying. Despite the advancement of NLP technologies, the automated cyberbullying detection remains challenging. This paper focuses on advancing the technology using state-of-the-art NLP techniques. We use a Twitter dataset from SemEval 2019 - Task 5(HatEval) on hate speech against women and immigrants. Our best performing ensemble model based on DistilBERT has achieved 0.73 and 0.74 of F1 score in the task of classifying hate speech (Task A) and aggressiveness and target (Task B) respectively. We adapt the ensemble model developed for Task A to classify offensive language in external datasets and achieved ~0.7 of F1 score using three benchmark datasets, enabling promising results for cross-domain adaptability. We conduct a qualitative analysis of misclassified tweets to provide insightful recommendations for future cyberbullying research.
Enhancing the Identification of Cyberbullying through Participant Roles
Oct 23, 2020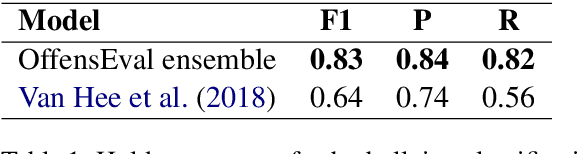
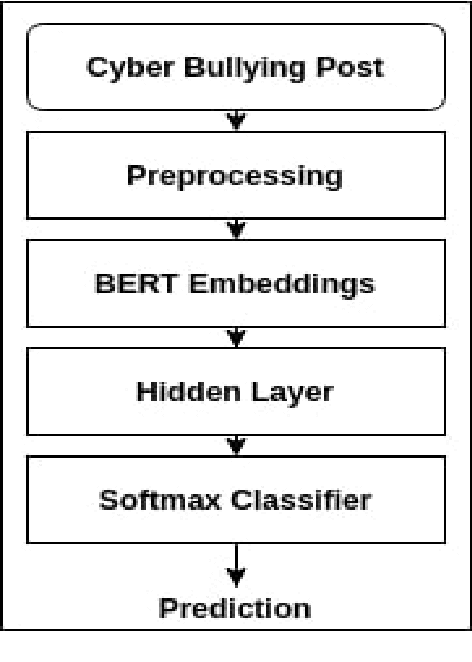
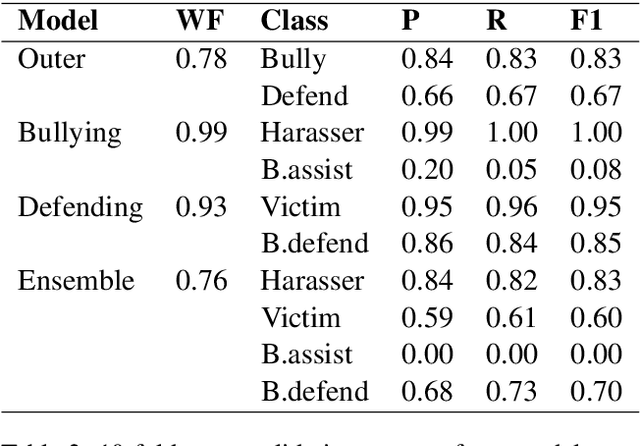
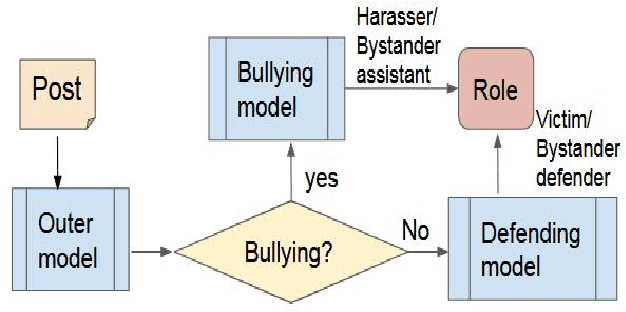
Cyberbullying is a prevalent social problem that inflicts detrimental consequences to the health and safety of victims such as psychological distress, anti-social behaviour, and suicide. The automation of cyberbullying detection is a recent but widely researched problem, with current research having a strong focus on a binary classification of bullying versus non-bullying. This paper proposes a novel approach to enhancing cyberbullying detection through role modeling. We utilise a dataset from ASKfm to perform multi-class classification to detect participant roles (e.g. victim, harasser). Our preliminary results demonstrate promising performance including 0.83 and 0.76 of F1-score for cyberbullying and role classification respectively, outperforming baselines.