 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaseline Detection in Historical Documents using Convolutional U-Nets
Oct 22, 2018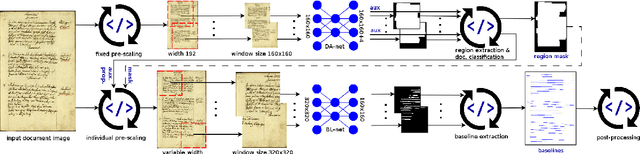
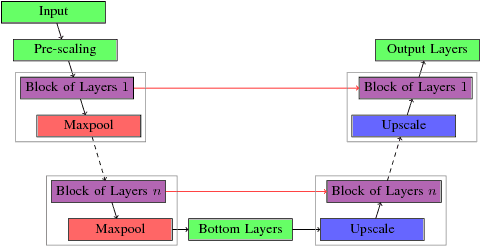


Baseline detection is still a challenging task for heterogeneous collections of historical documents. We present a novel approach to baseline extraction in such settings, turning out the winning entry to the ICDAR 2017 Competition on Baseline detection (cBAD). It utilizes deep convolutional nets (CNNs) for both, the actual extraction of baselines, as well as for a simple form of layout analysis in a pre-processing step. To the best of our knowledge it is the first CNN-based system for baseline extraction applying a U-net architecture and sliding window detection, profiting from a high local accuracy of the candidate lines extracted. Final baseline post-processing complements our approach, compensating for inaccuracies mainly due to missing context information during sliding window detection. We experimentally evaluate the components of our system individually on the cBAD dataset. Moreover, we investigate how it generalizes to different data by means of the dataset used for the baseline extraction task of the ICDAR 2017 Competition on Layout Analysis for Challenging Medieval Manuscripts (HisDoc). A comparison with the results reported for HisDoc shows that it also outperforms the contestants of the latter.
* 6 pages, accepted to DAS 2018