 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Real-Time Mortality Prediction in the Intensive Care Unit using Temporal Difference Learning
Nov 06, 2024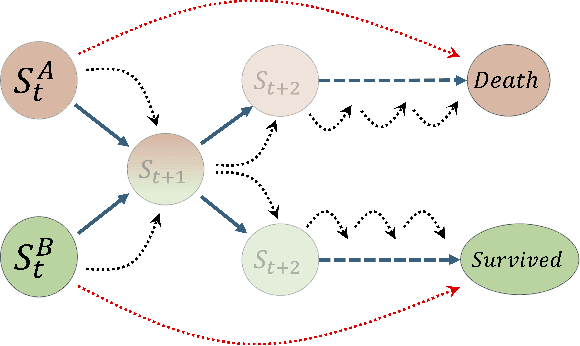
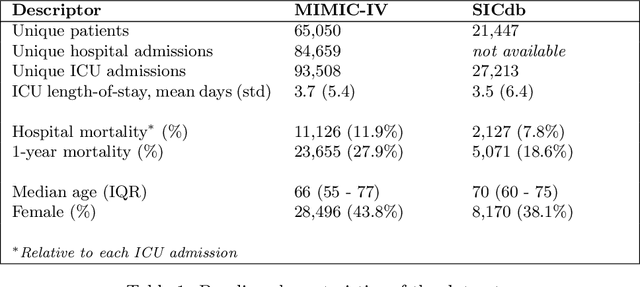
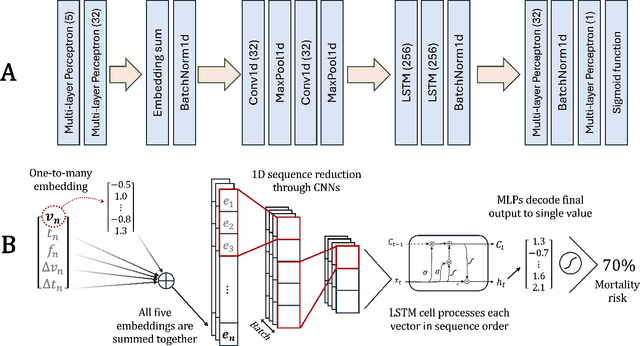
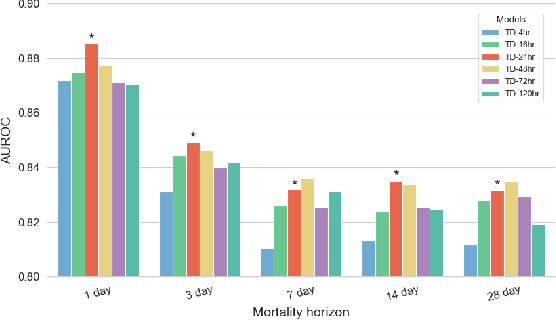
The task of predicting long-term patient outcomes using supervised machine learning is a challenging one, in part because of the high variance of each patient's trajectory, which can result in the model over-fitting to the training data. Temporal difference (TD) learning, a common reinforcement learning technique, may reduce variance by generalising learning to the pattern of state transitions rather than terminal outcomes. However, in healthcare this method requires several strong assumptions about patient states, and there appears to be limited literature evaluating the performance of TD learning against traditional supervised learning methods for long-term health outcome prediction tasks. In this study, we define a framework for applying TD learning to real-time irregularly sampled time series data using a Semi-Markov Reward Process. We evaluate the model framework in predicting intensive care mortality and show that TD learning under this framework can result in improved model robustness compared to standard supervised learning methods. and that this robustness is maintained even when validated on external datasets. This approach may offer a more reliable method when learning to predict patient outcomes using high-variance irregular time series data.