 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Low-Resource Cross-lingual Parsing with Expected Statistic Regularization
Oct 17, 2022
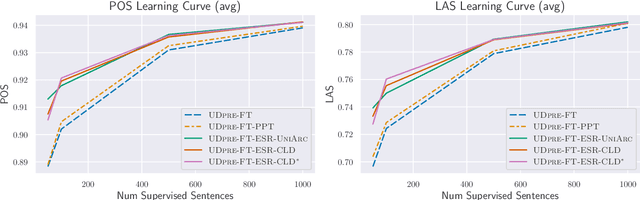
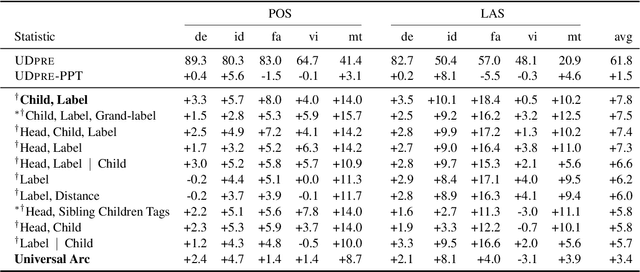
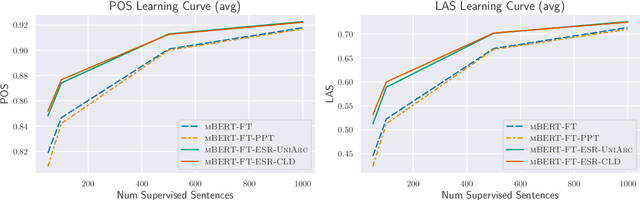
We present Expected Statistic Regularization (ESR), a novel regularization technique that utilizes low-order multi-task structural statistics to shape model distributions for semi-supervised learning on low-resource datasets. We study ESR in the context of cross-lingual transfer for syntactic analysis (POS tagging and labeled dependency parsing) and present several classes of low-order statistic functions that bear on model behavior. Experimentally, we evaluate the proposed statistics with ESR for unsupervised transfer on 5 diverse target languages and show that all statistics, when estimated accurately, yield improvements to both POS and LAS, with the best statistic improving POS by +7.0 and LAS by +8.5 on average. We also present semi-supervised transfer and learning curve experiments that show ESR provides significant gains over strong cross-lingual-transfer-plus-fine-tuning baselines for modest amounts of label data. These results indicate that ESR is a promising and complementary approach to model-transfer approaches for cross-lingual parsing.
Partially Supervised Named Entity Recognition via the Expected Entity Ratio Loss
Aug 16, 2021

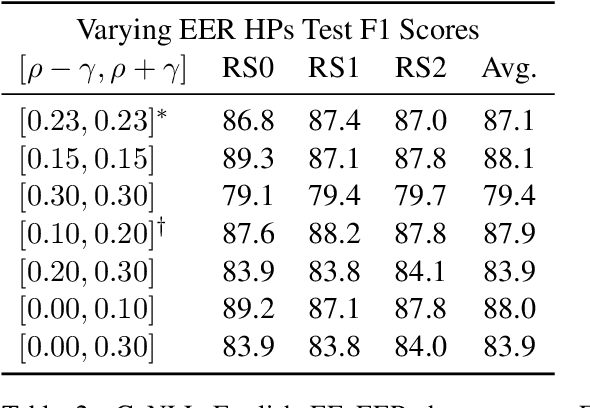

We study learning named entity recognizers in the presence of missing entity annotations. We approach this setting as tagging with latent variables and propose a novel loss, the Expected Entity Ratio, to learn models in the presence of systematically missing tags. We show that our approach is both theoretically sound and empirically useful. Experimentally, we find that it meets or exceeds performance of strong and state-of-the-art baselines across a variety of languages, annotation scenarios, and amounts of labeled data. In particular, we find that it significantly outperforms the previous state-of-the-art methods from Mayhew et al. (2019) and Li et al. (2021) by +12.7 and +2.3 F1 score in a challenging setting with only 1,000 biased annotations, averaged across 7 datasets. We also show that, when combined with our approach, a novel sparse annotation scheme outperforms exhaustive annotation for modest annotation budgets.