Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust stochastic parsing using the inside-outside algorithm
Dec 19, 1994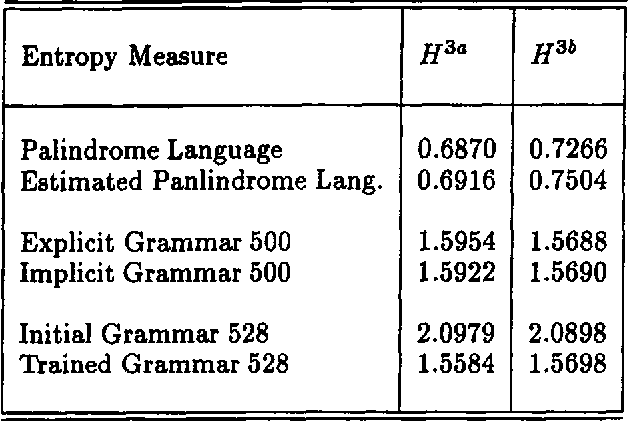
The paper describes a parser of sequences of (English) part-of-speech labels which utilises a probabilistic grammar trained using the inside-outside algorithm. The initial (meta)grammar is defined by a linguist and further rules compatible with metagrammatical constraints are automatically generated. During training, rules with very low probability are rejected yielding a wide-coverage parser capable of ranking alternative analyses. A series of corpus-based experiments describe the parser's performance.
* Revised and updated version of paper from AAAI Workshop on
Probabilistically-based Natural Language Processing Techniques, 1992, 16
pages, uuencoded, compressed postscript
Via