 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Context Selection for Retrieval-Augmented Generation: Mitigating Distractors and Positional Bias
Dec 16, 2025

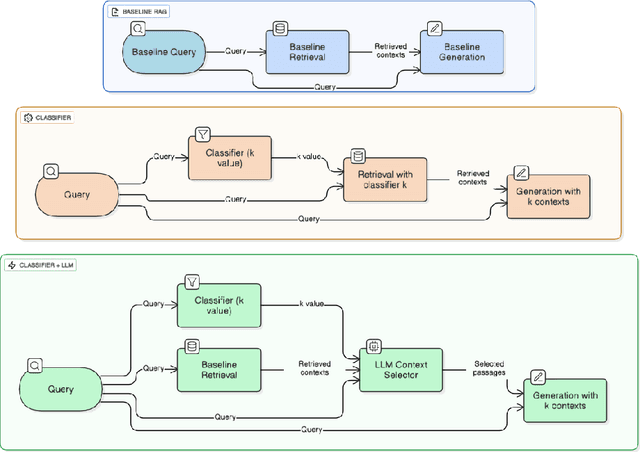

Retrieval Augmented Generation (RAG) enhances language model performance by incorporating external knowledge retrieved from large corpora, which makes it highly suitable for tasks such as open domain question answering. Standard RAG systems typically rely on a fixed top k retrieval strategy, which can either miss relevant information or introduce semantically irrelevant passages, known as distractors, that degrade output quality. Additionally, the positioning of retrieved passages within the input context can influence the model attention and generation outcomes. Context placed in the middle tends to be overlooked, which is an issue known as the "lost in the middle" phenomenon. In this work, we systematically analyze the impact of distractors on generation quality, and quantify their effects under varying conditions. We also investigate how the position of relevant passages within the context window affects their influence on generation. Building on these insights, we propose a context-size classifier that dynamically predicts the optimal number of documents to retrieve based on query-specific informational needs. We integrate this approach into a full RAG pipeline, and demonstrate improved performance over fixed k baselines.
Exploring Large Language Models and Hierarchical Frameworks for Classification of Large Unstructured Legal Documents
Mar 11, 2024Legal judgment prediction suffers from the problem of long case documents exceeding tens of thousands of words, in general, and having a non-uniform structure. Predicting judgments from such documents becomes a challenging task, more so on documents with no structural annotation. We explore the classification of these large legal documents and their lack of structural information with a deep-learning-based hierarchical framework which we call MESc; "Multi-stage Encoder-based Supervised with-clustering"; for judgment prediction. Specifically, we divide a document into parts to extract their embeddings from the last four layers of a custom fine-tuned Large Language Model, and try to approximate their structure through unsupervised clustering. Which we use in another set of transformer encoder layers to learn the inter-chunk representations. We analyze the adaptability of Large Language Models (LLMs) with multi-billion parameters (GPT-Neo, and GPT-J) with the hierarchical framework of MESc and compare them with their standalone performance on legal texts. We also study their intra-domain(legal) transfer learning capability and the impact of combining embeddings from their last layers in MESc. We test these methods and their effectiveness with extensive experiments and ablation studies on legal documents from India, the European Union, and the United States with the ILDC dataset and a subset of the LexGLUE dataset. Our approach achieves a minimum total performance gain of approximately 2 points over previous state-of-the-art methods.
Exploring Semi-supervised Hierarchical Stacked Encoder for Legal Judgement Prediction
Nov 14, 2023Predicting the judgment of a legal case from its unannotated case facts is a challenging task. The lengthy and non-uniform document structure poses an even greater challenge in extracting information for decision prediction. In this work, we explore and propose a two-level classification mechanism; both supervised and unsupervised; by using domain-specific pre-trained BERT to extract information from long documents in terms of sentence embeddings further processing with transformer encoder layer and use unsupervised clustering to extract hidden labels from these embeddings to better predict a judgment of a legal case. We conduct several experiments with this mechanism and see higher performance gains than the previously proposed methods on the ILDC dataset. Our experimental results also show the importance of domain-specific pre-training of Transformer Encoders in legal information processing.