 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Correlations Between Intrinsic and Extrinsic Bias Metrics of Static Word Embeddings With Their Measuring Biases Aligned
Sep 14, 2024
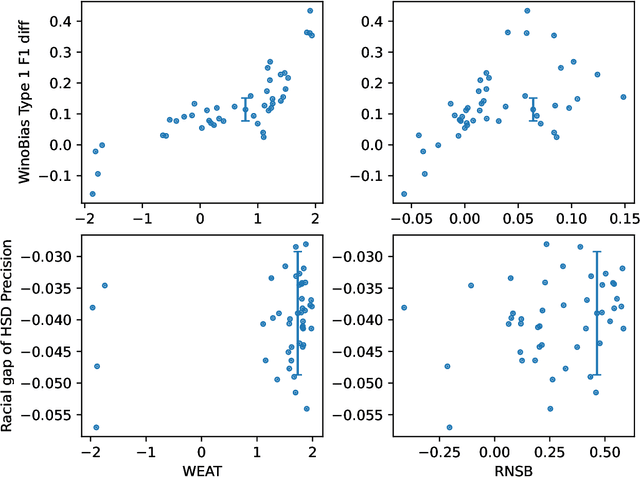

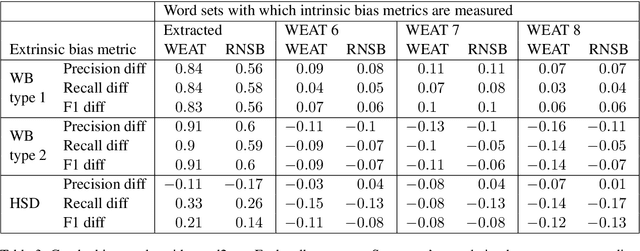
We examine the abilities of intrinsic bias metrics of static word embeddings to predict whether Natural Language Processing (NLP) systems exhibit biased behavior. A word embedding is one of the fundamental NLP technologies that represents the meanings of words through real vectors, and problematically, it also learns social biases such as stereotypes. An intrinsic bias metric measures bias by examining a characteristic of vectors, while an extrinsic bias metric checks whether an NLP system trained with a word embedding is biased. A previous study found that a common intrinsic bias metric usually does not correlate with extrinsic bias metrics. However, the intrinsic and extrinsic bias metrics did not measure the same bias in most cases, which makes us question whether the lack of correlation is genuine. In this paper, we extract characteristic words from datasets of extrinsic bias metrics and analyze correlations with intrinsic bias metrics with those words to ensure both metrics measure the same bias. We observed moderate to high correlations with some extrinsic bias metrics but little to no correlations with the others. This result suggests that intrinsic bias metrics can predict biased behavior in particular settings but not in others. Experiment codes are available at GitHub.