 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-19 Literature Mining and Retrieval using Text Mining Approaches
May 29, 2022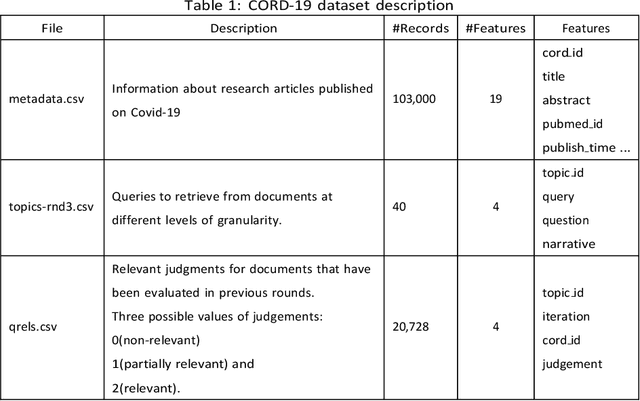
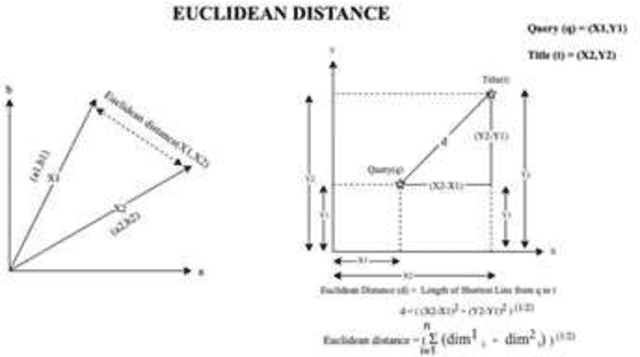

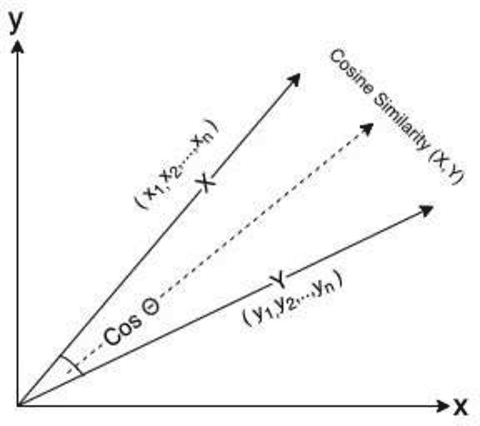
The novel coronavirus disease (COVID-19) began in Wuhan, China, in late 2019 and to date has infected over 148M people worldwide, resulting in 3.12M deaths. On March 10, 2020, the World Health Organisation (WHO) declared it as a global pandemic. Many academicians and researchers started to publish papers describing the latest discoveries on covid-19. The large influx of publications made it hard for other researchers to go through a large amount of data and find the appropriate one that helps their research. So, the proposed model attempts to extract relavent titles from the large corpus of research publications which makes the job easy for the researchers. Allen Institute for AI released the CORD-19 dataset, which consists of 2,00,000 journal articles related to coronavirus-related research publications from PubMed's PMC, WHO (World Health Organization), bioRxiv, and medRxiv pre-prints. Along with this document corpus, they have also provided a topics dataset named topics-rnd3 consisting of a list of topics. Each topic has three types of representations like query, question, and narrative. These Datasets are made open for research, and also they released a TREC-COVID competition on Kaggle. Using these topics like queries, our goal is to find out the relevant documents in the CORD-19 dataset. In this research, relevant documents should be recognized for the posed topics in topics-rnd3 data set. The proposed model uses Natural Language Processing(NLP) techniques like Bag-of-Words, Average Word-2-Vec, Average BERT Base model and Tf-Idf weighted Word2Vec model to fabricate vectors for query, question, narrative, and combinations of them. Similarly, fabricate vectors for titles in the CORD-19 dataset. After fabricating vectors, cosine similarity is used for finding similarities between every two vectors. Cosine similarity helps us to find relevant documents for the given topic.
Classifying Human Activities using Machine Learning and Deep Learning Techniques
May 19, 2022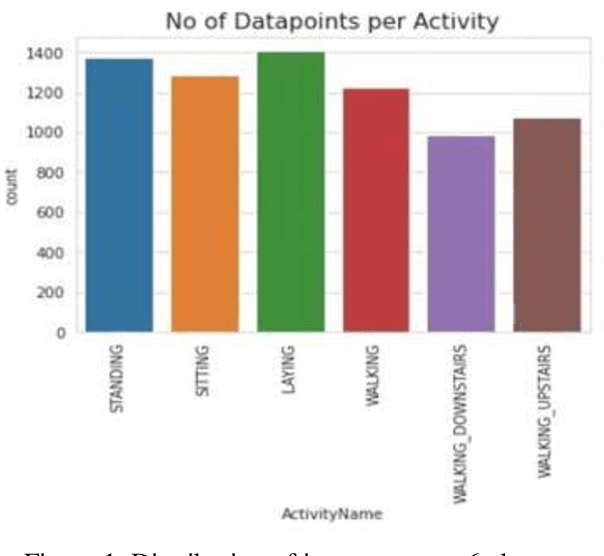



Human Activity Recognition (HAR) describes the machines ability to recognize human actions. Nowadays, most people on earth are health conscious, so people are more interested in tracking their daily activities using Smartphones or Smart Watches, which can help them manage their daily routines in a healthy way. With this objective, Kaggle has conducted a competition to classify 6 different human activities distinctly based on the inertial signals obtained from 30 volunteers smartphones. The main challenge in HAR is to overcome the difficulties of separating human activities based on the given data such that no two activities overlap. In this experimentation, first, Data visualization is done on expert generated features with the help of t distributed Stochastic Neighborhood Embedding followed by applying various Machine Learning techniques like Logistic Regression, Linear SVC, Kernel SVM, Decision trees to better classify the 6 distinct human activities. Moreover, Deep Learning techniques like Long Short-Term Memory (LSTM), Bi-Directional LSTM, Recurrent Neural Network (RNN), and Gated Recurrent Unit (GRU) are trained using raw time series data. Finally, metrics like Accuracy, Confusion matrix, precision and recall are used to evaluate the performance of the Machine Learning and Deep Learning models. Experiment results proved that the Linear Support Vector Classifier in machine learning and Gated Recurrent Unit in Deep Learning provided better accuracy for human activity recognition compared to other classifiers.
Link Prediction Approach to Recommender Systems
Feb 18, 2021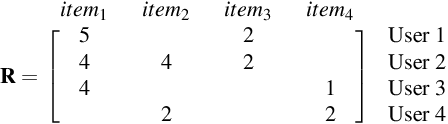

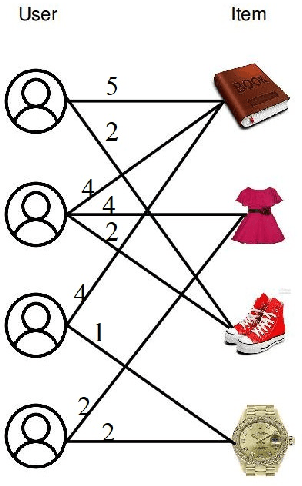

The problem of recommender system is very popular with myriad available solutions. A novel approach that uses the link prediction problem in social networks has been proposed in the literature that model the typical user-item information as a bipartite network in which link prediction would actually mean recommending an item to a user. The standard recommender system methods suffer from the problems of sparsity and scalability. Since link prediction measures involve computations pertaining to small neighborhoods in the network, this approach would lead to a scalable solution to recommendation. One of the issues in this conversion is that link prediction problem is modelled as a binary classification task whereas the problem of recommender systems is solved as a regression task in which the rating of the link is to be predicted. We overcome this issue by predicting top k links as recommendations with high ratings without predicting the actual rating. Our work extends similar approaches in the literature by focusing on exploiting the probabilistic measures for link prediction. Moreover, in the proposed approach, prediction measures that utilize temporal information available on the links prove to be more effective in improving the accuracy of prediction. This approach is evaluated on the benchmark 'Movielens' dataset. We show that the usage of temporal probabilistic measures helps in improving the quality of recommendations. Temporal random-walk based measure T_Flow improves recommendation accuracy by 4% and Temporal cooccurrence probability measure improves prediction accuracy by 10% over item-based collaborative filtering method in terms of AUROC score.