 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumerical Atrribute Extraction from Clinical Texts
Jan 31, 2016
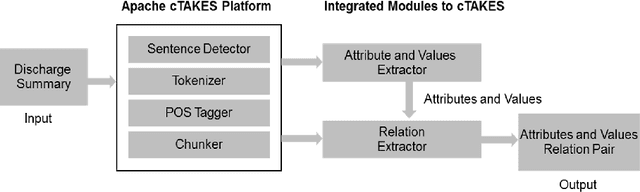
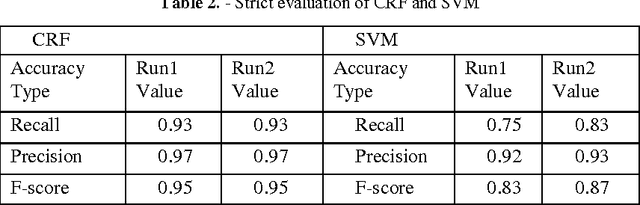
This paper describes about information extraction system, which is an extension of the system developed by team Hitachi for "Disease/Disorder Template filling" task organized by ShARe/CLEF eHealth Evolution Lab 2014. In this extension module we focus on extraction of numerical attributes and values from discharge summary records and associating correct relation between attributes and values. We solve the problem in two steps. First step is extraction of numerical attributes and values, which is developed as a Named Entity Recognition (NER) model using Stanford NLP libraries. Second step is correctly associating the attributes to values, which is developed as a relation extraction module in Apache cTAKES framework. We integrated Stanford NER model as cTAKES pipeline component and used in relation extraction module. Conditional Random Field (CRF) algorithm is used for NER and Support Vector Machines (SVM) for relation extraction. For attribute value relation extraction, we observe 95% accuracy using NER alone and combined accuracy of 87% with NER and SVM.