 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Visual Semantics: Exploring the Role of Scene Text in Image Understanding
May 25, 2019
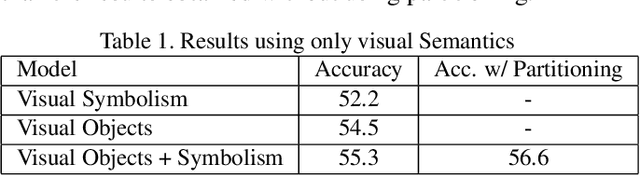
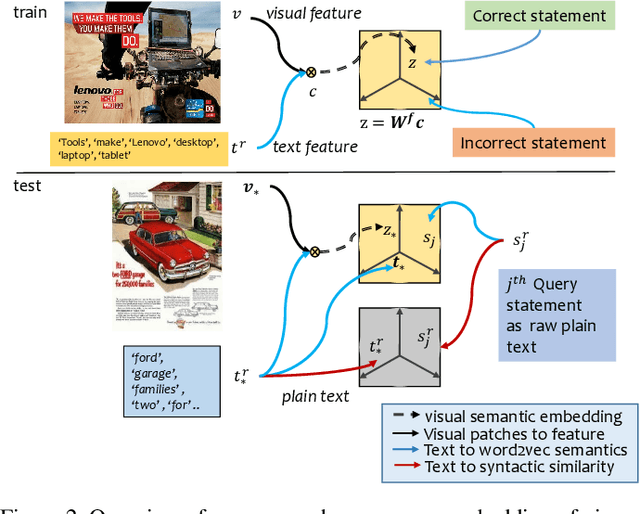

Images with visual and scene text content are ubiquitous in everyday life. However current image interpretation systems are mostly limited to using only the visual features, neglecting to leverage the scene text content. In this paper we propose to jointly use scene text and visual channels for robust semantic interpretation of images. We undertake the task of matching Advertisement images against their human generated statements that describe the action that the ad prompts and the rationale it provides for taking this action. We extract the scene text and generate semantic and lexical text representations, which are used in the interpretation of the Ad Image. To deal with irrelevant or erroneous detection of scene text, we use a text attention scheme. We also learn an embedding of the visual channel,\ie visual features based on detected symbolism and objects, into a semantic embedding space, leveraging text semantics obtained from scene text. We show how the multi channel approach, involving visual semantics and scene text, improves upon the current state of the art.