 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric-Based In-context Learning: A Case Study in Text Simplification
Jul 27, 2023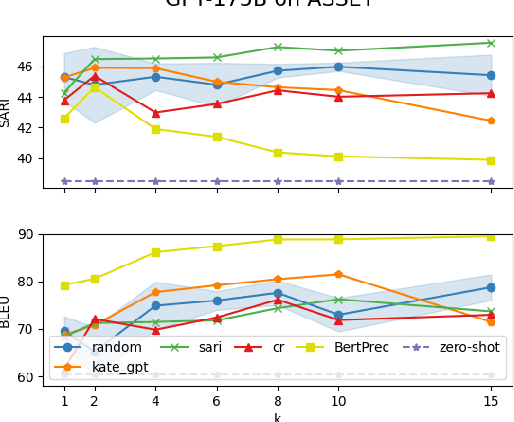



In-context learning (ICL) for large language models has proven to be a powerful approach for many natural language processing tasks. However, determining the best method to select examples for ICL is nontrivial as the results can vary greatly depending on the quality, quantity, and order of examples used. In this paper, we conduct a case study on text simplification (TS) to investigate how to select the best and most robust examples for ICL. We propose Metric-Based in-context Learning (MBL) method that utilizes commonly used TS metrics such as SARI, compression ratio, and BERT-Precision for selection. Through an extensive set of experiments with various-sized GPT models on standard TS benchmarks such as TurkCorpus and ASSET, we show that examples selected by the top SARI scores perform the best on larger models such as GPT-175B, while the compression ratio generally performs better on smaller models such as GPT-13B and GPT-6.7B. Furthermore, we demonstrate that MBL is generally robust to example orderings and out-of-domain test sets, and outperforms strong baselines and state-of-the-art finetuned language models. Finally, we show that the behaviour of large GPT models can be implicitly controlled by the chosen metric. Our research provides a new framework for selecting examples in ICL, and demonstrates its effectiveness in text simplification tasks, breaking new ground for more accurate and efficient NLG systems.