Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText normalization for endangered languages: the case of Ligurian
Jun 16, 2022
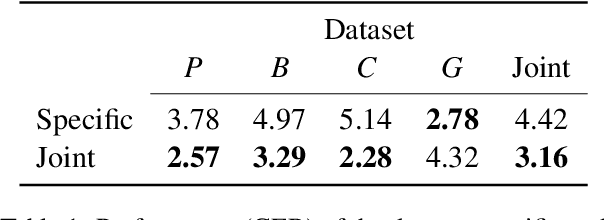
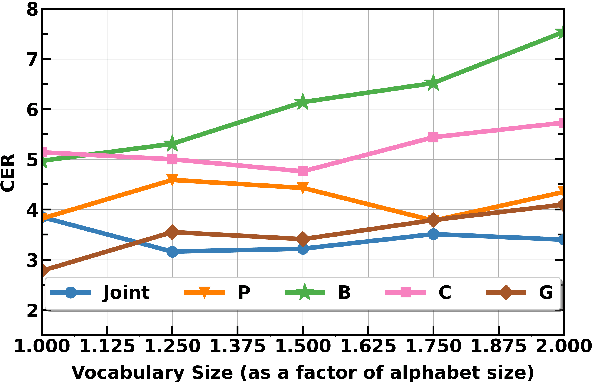
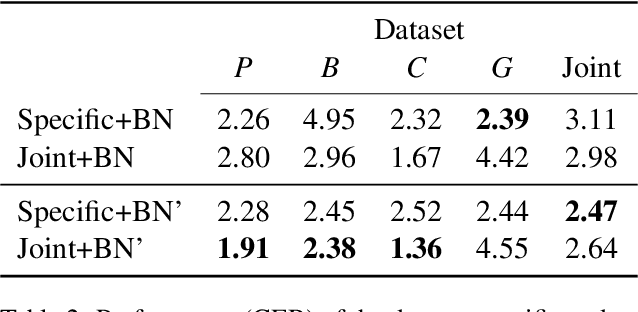
Text normalization is a crucial technology for low-resource languages which lack rigid spelling conventions. Low-resource text normalization has so far relied upon hand-crafted rules, which are perceived to be more data efficient than neural methods. In this paper we examine the case of text normalization for Ligurian, an endangered Romance language. We collect 4,394 Ligurian sentences paired with their normalized versions, as well as the first monolingual corpus for Ligurian. We show that, in spite of the small amounts of data available, a compact transformer-based model can be trained to achieve very low error rates by the use of backtranslation and appropriate tokenization. Our datasets are released to the public.
Via