 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Relative Depth between Objects from Semantic Features
Jan 12, 2021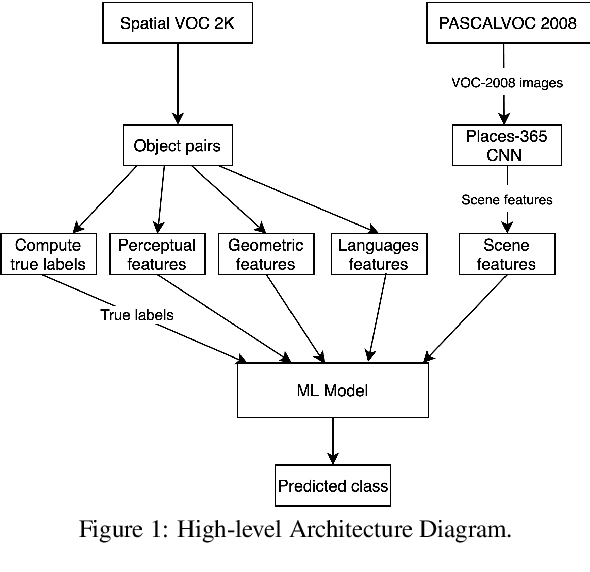

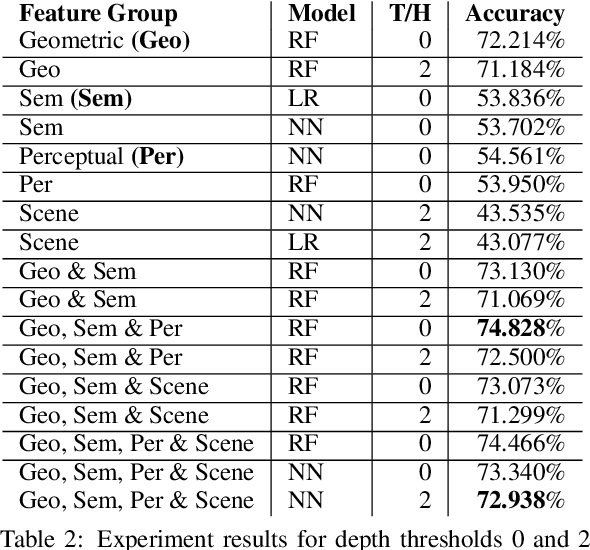
Vision and language tasks such as Visual Relation Detection and Visual Question Answering benefit from semantic features that afford proper grounding of language. The 3D depth of objects depicted in 2D images is one such feature. However it is very difficult to obtain accurate depth information without learning the appropriate features, which are scene dependent. The state of the art in this area are complex Neural Network models trained on stereo image data to predict depth per pixel. Fortunately, in some tasks, its only the relative depth between objects that is required. In this paper the extent to which semantic features can predict course relative depth is investigated. The problem is casted as a classification one and geometrical features based on object bounding boxes, object labels and scene attributes are computed and used as inputs to pattern recognition models to predict relative depth. i.e behind, in-front and neutral. The results are compared to those obtained from averaging the output of the monodepth neural network model, which represents the state-of-the art. An overall increase of 14% in relative depth accuracy over relative depth computed from the monodepth model derived results is achieved.