 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTocBERT: Medical Document Structure Extraction Using Bidirectional Transformers
Jun 27, 2024

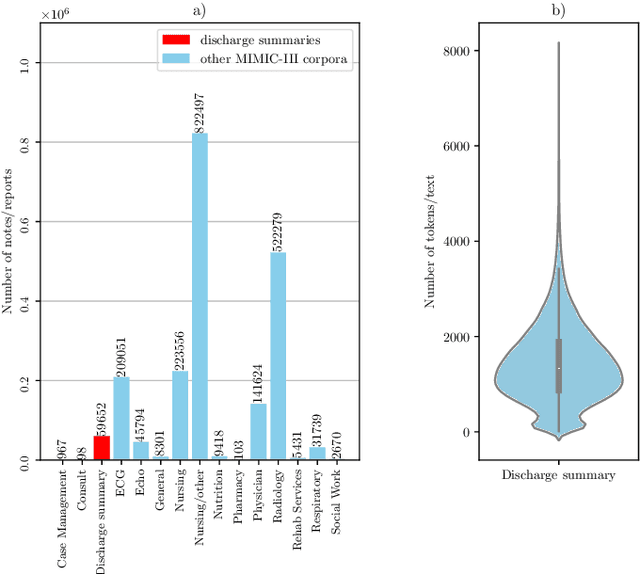

Text segmentation holds paramount importance in the field of Natural Language Processing (NLP). It plays an important role in several NLP downstream tasks like information retrieval and document summarization. In this work, we propose a new solution, namely TocBERT, for segmenting texts using bidirectional transformers. TocBERT represents a supervised solution trained on the detection of titles and sub-titles from their semantic representations. This task was formulated as a named entity recognition (NER) problem. The solution has been applied on a medical text segmentation use-case where the Bio-ClinicalBERT model is fine-tuned to segment discharge summaries of the MIMIC-III dataset. The performance of TocBERT has been evaluated on a human-labeled ground truth corpus of 250 notes. It achieved an F1-score of 84.6% when evaluated on a linear text segmentation problem and 72.8% on a hierarchical text segmentation problem. It outperformed a carefully designed rule-based solution, particularly in distinguishing titles from subtitles.
Anatomy of Neural Language Models
Jan 08, 2024Generative AI and transfer learning fields have experienced remarkable advancements in recent years especially in the domain of Natural Language Processing (NLP). Transformers were at the heart of these advancements where the cutting-edge transformer-based Language Models (LMs) enabled new state-of-the-art results in a wide spectrum of applications. While the number of research works involving neural LMs is exponentially increasing, their vast majority are high-level and far from self-contained. Consequently, a deep understanding of the literature in this area is a tough task especially at the absence of a unified mathematical framework explaining the main types of neural LMs. We address the aforementioned problem in this tutorial where the objective is to explain neural LMs in a detailed, simplified and unambiguous mathematical framework accompanied with clear graphical illustrations. Concrete examples on widely used models like BERT and GPT2 are explored. Finally, since transformers pretrained on language-modeling-like tasks have been widely adopted in computer vision and time series applications, we briefly explore some examples of such solutions in order to enable readers understand how transformers work in the aforementioned domains and compare this use with the original one in NLP.
Deep learning for location based beamforming with NLOS channels
Dec 29, 2021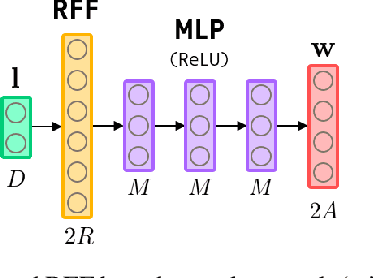
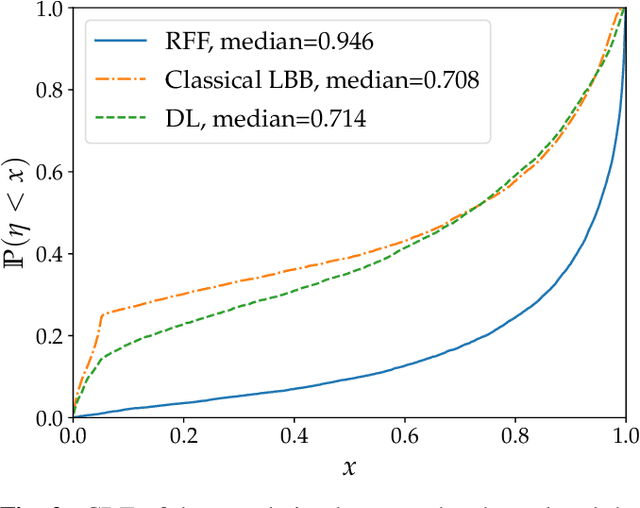
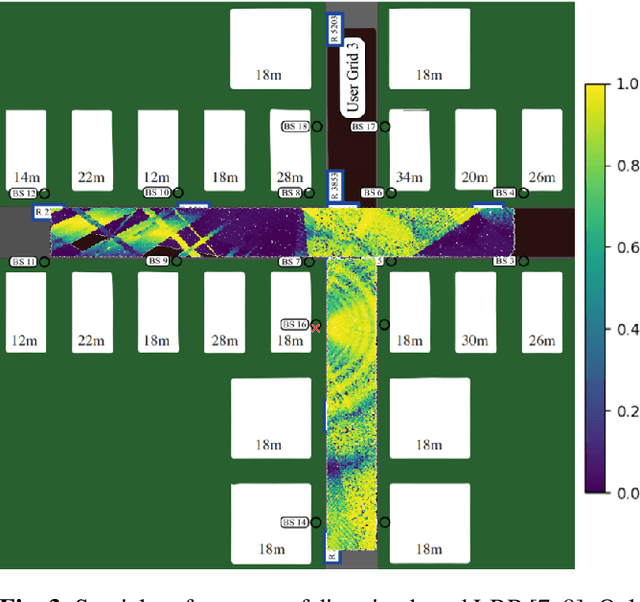
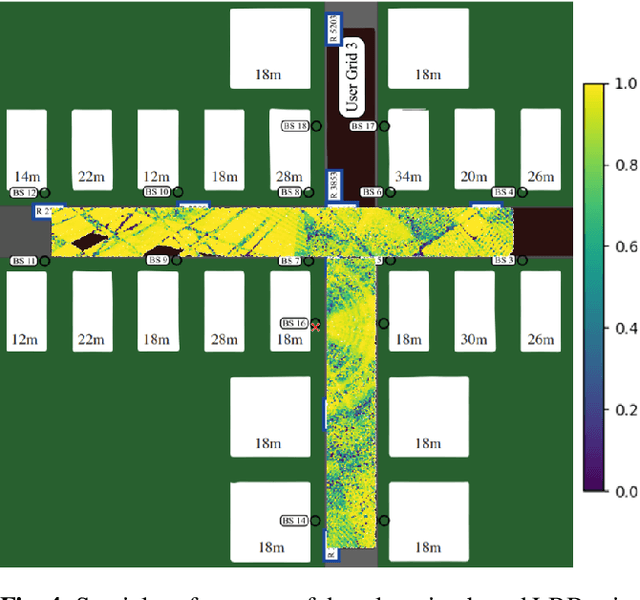
Massive MIMO systems are highly efficient but critically rely on accurate channel state information (CSI) at the base station in order to determine appropriate precoders. CSI acquisition requires sending pilot symbols which induce an important overhead. In this paper, a method whose objective is to determine an appropriate precoder from the knowledge of the user's location only is proposed. Such a way to determine precoders is known as location based beamforming. It allows to reduce or even eliminate the need for pilot symbols, depending on how the location is obtained. the proposed method learns a direct mapping from location to precoder in a supervised way. It involves a neural network with a specific structure based on random Fourier features allowing to learn functions containing high spatial frequencies. It is assessed empirically and yields promising results on realistic synthetic channels. As opposed to previously proposed methods, it allows to handle both line-of-sight (LOS) and non-line-of-sight (NLOS) channels.
Online unsupervised deep unfolding for massive MIMO channel estimation
Apr 30, 2020



Massive MIMO communication systems have a huge potential both in terms of data rate and energy efficiency, although channel estimation becomes challenging for a large number antennas. Using a physical model allows to ease the problem by injecting a priori information based on the physics of propagation. However, such a model rests on simplifying assumptions and requires to know precisely the configuration of the system, which is unrealistic in practice. In this letter, we propose to add flexibility to physical channel models by unfolding the channel estimation algorithms as neural networks. This leads to a neural network structure that can be trained online when initialized with an imperfect model, realizing automatic system calibration. The method is applied to both single path and multipath realistic millimeter wave channels and shows great performance, achieving a channel estimation error almost as low as one would get with a perfectly calibrated system.