 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Parity Challenges in Reinforcement Learning through Curriculum Learning with Noisy Labels
Dec 08, 2023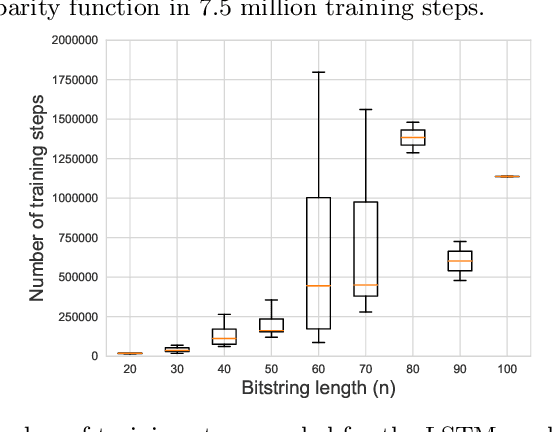

This paper delves into applying reinforcement learning (RL) in strategy games, particularly those characterized by parity challenges, as seen in specific positions of Go and Chess and a broader range of impartial games. We propose a simulated learning process, structured within a curriculum learning framework and augmented with noisy labels, to mirror the intricacies of self-play learning scenarios. This approach thoroughly analyses how neural networks (NNs) adapt and evolve from elementary to increasingly complex game positions. Our empirical research indicates that even minimal label noise can significantly impede NNs' ability to discern effective strategies, a difficulty that intensifies with the growing complexity of the game positions. These findings underscore the urgent need for advanced methodologies in RL training, specifically tailored to counter the obstacles imposed by noisy evaluations. The development of such methodologies is crucial not only for enhancing NN proficiency in strategy games with significant parity elements but also for broadening the resilience and efficiency of RL systems across diverse and complex environments.