 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Plagiarism Detection Systems: Case of Use with English, French and Arabic Languages
Jan 10, 2022
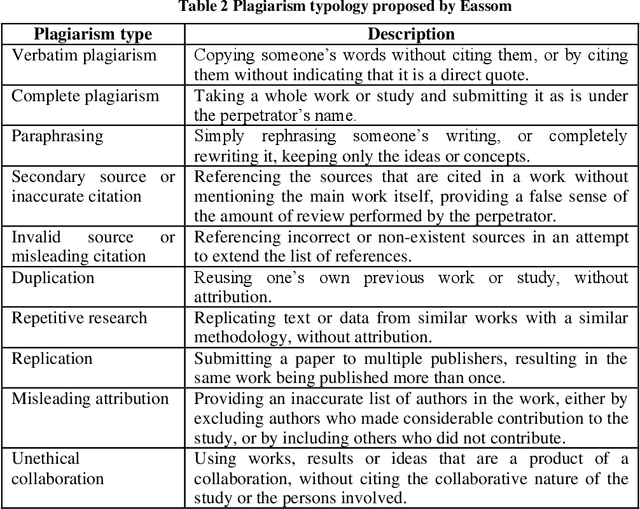


In academia, plagiarism is certainly not an emerging concern, but it became of a greater magnitude with the popularisation of the Internet and the ease of access to a worldwide source of content, rendering human-only intervention insufficient. Despite that, plagiarism is far from being an unaddressed problem, as computer-assisted plagiarism detection is currently an active area of research that falls within the field of Information Retrieval (IR) and Natural Language Processing (NLP). Many software solutions emerged to help fulfil this task, and this paper presents an overview of plagiarism detection systems for use in Arabic, French, and English academic and educational settings. The comparison was held between eight systems and was performed with respect to their features, usability, technical aspects, as well as their performance in detecting three levels of obfuscation from different sources: verbatim, paraphrase, and cross-language plagiarism. An indepth examination of technical forms of plagiarism was also performed in the context of this study. In addition, a survey of plagiarism typologies and classifications proposed by different authors is provided.