 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTicket-BERT: Labeling Incident Management Tickets with Language Models
Jun 30, 2023An essential aspect of prioritizing incident tickets for resolution is efficiently labeling tickets with fine-grained categories. However, ticket data is often complex and poses several unique challenges for modern machine learning methods: (1) tickets are created and updated either by machines with pre-defined algorithms or by engineers with domain expertise that share different protocols, (2) tickets receive frequent revisions that update ticket status by modifying all or parts of ticket descriptions, and (3) ticket labeling is time-sensitive and requires knowledge updates and new labels per the rapid software and hardware improvement lifecycle. To handle these issues, we introduce Ticket- BERT which trains a simple yet robust language model for labeling tickets using our proposed ticket datasets. Experiments demonstrate the superiority of Ticket-BERT over baselines and state-of-the-art text classifiers on Azure Cognitive Services. We further encapsulate Ticket-BERT with an active learning cycle and deploy it on the Microsoft IcM system, which enables the model to quickly finetune on newly-collected tickets with a few annotations.
BERTVision -- A Parameter-Efficient Approach for Question Answering
Feb 24, 2022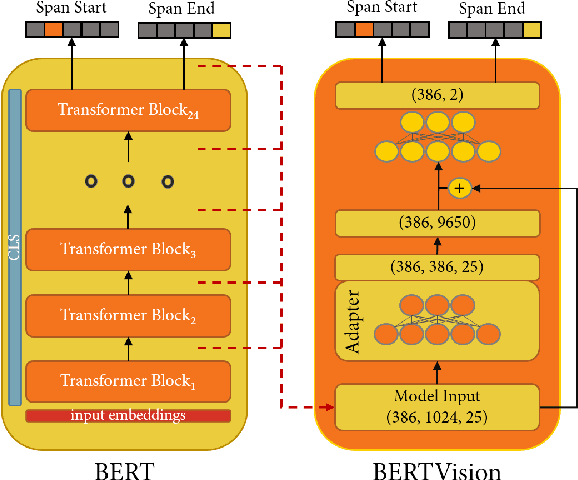
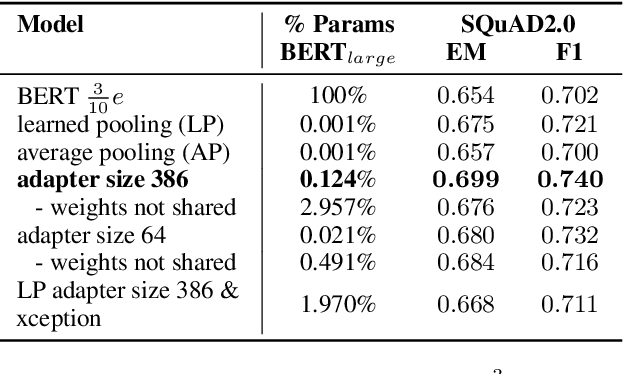
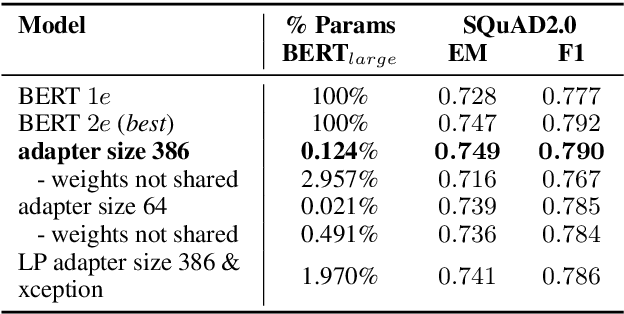
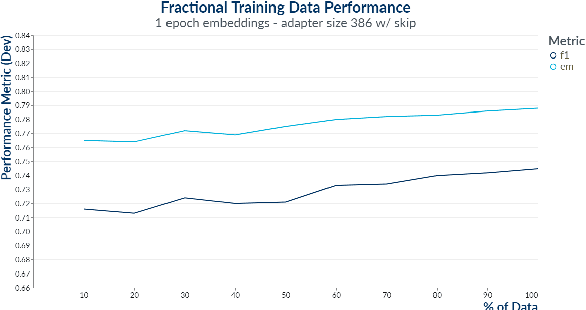
We present a highly parameter efficient approach for Question Answering that significantly reduces the need for extended BERT fine-tuning. Our method uses information from the hidden state activations of each BERT transformer layer, which is discarded during typical BERT inference. Our best model achieves maximal BERT performance at a fraction of the training time and GPU or TPU expense. Performance is further improved by ensembling our model with BERTs predictions. Furthermore, we find that near optimal performance can be achieved for QA span annotation using less training data. Our experiments show that this approach works well not only for span annotation, but also for classification, suggesting that it may be extensible to a wider range of tasks.