 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUzbek text summarization based on TF-IDF
Mar 01, 2023The volume of information is increasing at an incredible rate with the rapid development of the Internet and electronic information services. Due to time constraints, we don't have the opportunity to read all this information. Even the task of analyzing textual data related to one field requires a lot of work. The text summarization task helps to solve these problems. This article presents an experiment on summarization task for Uzbek language, the methodology was based on text abstracting based on TF-IDF algorithm. Using this density function, semantically important parts of the text are extracted. We summarize the given text by applying the n-gram method to important parts of the whole text. The authors used a specially handcrafted corpus called "School corpus" to evaluate the performance of the proposed method. The results show that the proposed approach is effective in extracting summaries from Uzbek language text and can potentially be used in various applications such as information retrieval and natural language processing. Overall, this research contributes to the growing body of work on text summarization in under-resourced languages.
Accuracy of the Uzbek stop words detection: a case study on "School corpus"
Sep 15, 2022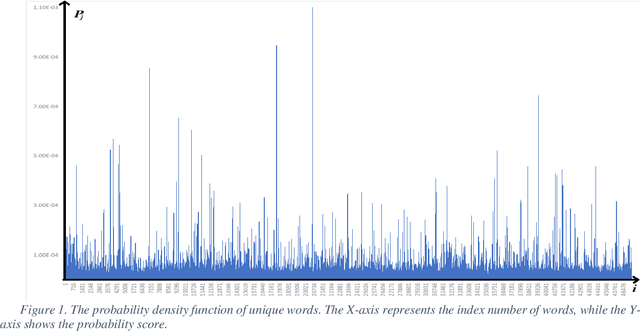

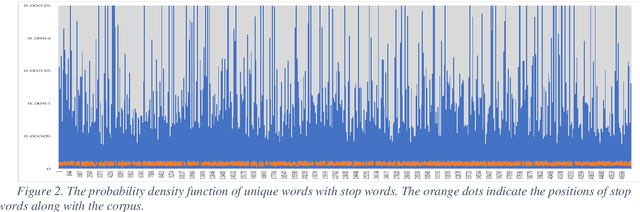
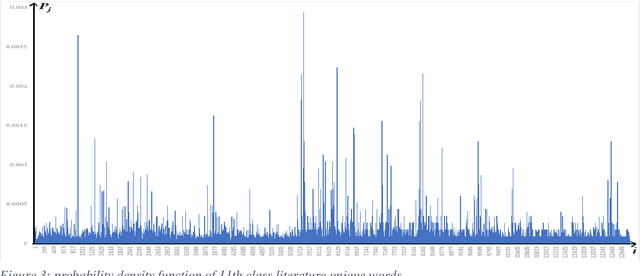
Stop words are very important for information retrieval and text analysis investigation tasks of natural language processing. Current work presents a method to evaluate the quality of a list of stop words aimed at automatically creating techniques. Although the method proposed in this paper was tested on an automatically-generated list of stop words for the Uzbek language, it can be, with some modifications, applied to similar languages either from the same family or the ones that have an agglutinative nature. Since the Uzbek language belongs to the family of agglutinative languages, it can be explained that the automatic detection of stop words in the language is a more complex process than in inflected languages. Moreover, we integrated our previous work on stop words detection in the example of the "School corpus" by investigating how to automatically analyse the detection of stop words in Uzbek texts. This work is devoted to answering whether there is a good way of evaluating available stop words for Uzbek texts, or whether it is possible to determine what part of the Uzbek sentence contains the majority of the stop words by studying the numerical characteristics of the probability of unique words. The results show acceptable accuracy of the stop words lists.