 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowGraph@IITK at SemEval-2021 Task 11: Building KnowledgeGraph for NLP Research
Apr 04, 2021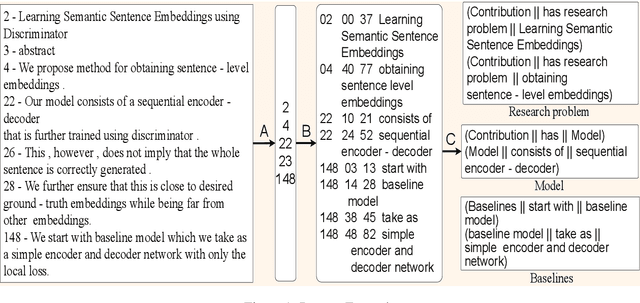

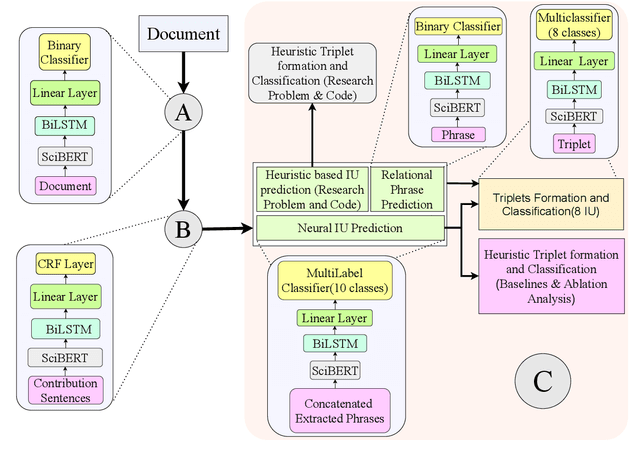
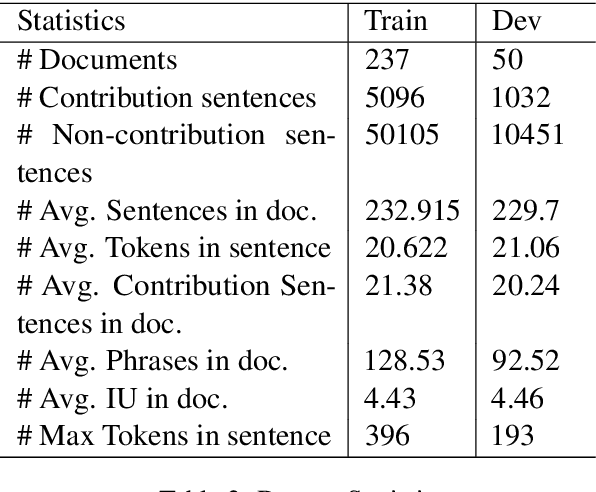
Research in Natural Language Processing is making rapid advances, resulting in the publication of a large number of research papers. Finding relevant research papers and their contribution to the domain is a challenging problem. In this paper, we address this challenge via the SemEval 2021 Task 11: NLPContributionGraph, by developing a system for a research paper contributions-focused knowledge graph over Natural Language Processing literature. The task is divided into three sub-tasks: extracting contribution sentences that show important contributions in the research article, extracting phrases from the contribution sentences, and predicting the information units in the research article together with triplet formation from the phrases. The proposed system is agnostic to the subject domain and can be applied for building a knowledge graph for any area. We found that transformer-based language models can significantly improve existing techniques and utilized the SciBERT-based model. Our first sub-task uses Bidirectional LSTM (BiLSTM) stacked on top of SciBERT model layers, while the second sub-task uses Conditional Random Field (CRF) on top of SciBERT with BiLSTM. The third sub-task uses a combined SciBERT based neural approach with heuristics for information unit prediction and triplet formation from the phrases. Our system achieved F1 score of 0.38, 0.63 and 0.76 in end-to-end pipeline testing, phrase extraction testing and triplet extraction testing respectively.
TAN-NTM: Topic Attention Networks for Neural Topic Modeling
Dec 02, 2020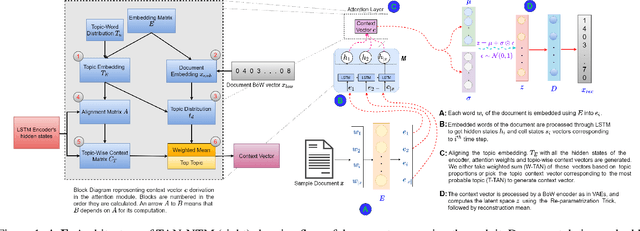
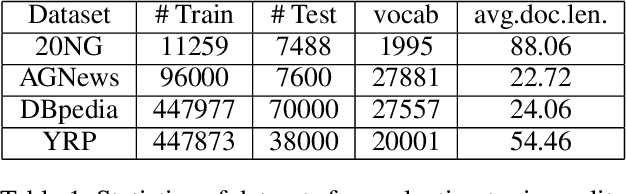
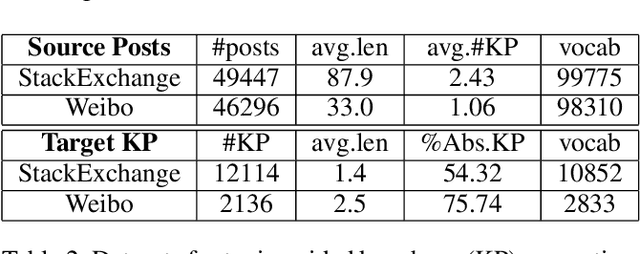

Topic models have been widely used to learn representations from text and gain insight into document corpora. To perform topic discovery, existing neural models use document bag-of-words (BoW) representation as input followed by variational inference and learn topic-word distribution through reconstructing BoW. Such methods have mainly focused on analysing the effect of enforcing suitable priors on document distribution. However, little importance has been given to encoding improved document features for capturing document semantics better. In this work, we propose a novel framework: TAN-NTM which models document as a sequence of tokens instead of BoW at the input layer and processes it through an LSTM whose output is used to perform variational inference followed by BoW decoding. We apply attention on LSTM outputs to empower the model to attend on relevant words which convey topic related cues. We hypothesise that attention can be performed effectively if done in a topic guided manner and establish this empirically through ablations. We factor in topic-word distribution to perform topic aware attention achieving state-of-the-art results with ~9-15 percentage improvement over score of existing SOTA topic models in NPMI coherence metric on four benchmark datasets - 20NewsGroup, Yelp, AGNews, DBpedia. TAN-NTM also obtains better document classification accuracy owing to learning improved document-topic features. We qualitatively discuss that attention mechanism enables unsupervised discovery of keywords. Motivated by this, we further show that our proposed framework achieves state-of-the-art performance on topic aware supervised generation of keyphrases on StackExchange and Weibo datasets.