 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoPoseVR: Spatiotemporal Multi-Modal Reasoning for Egocentric Full-Body Pose in Virtual Reality
Feb 05, 2026Immersive virtual reality (VR) applications demand accurate, temporally coherent full-body pose tracking. Recent head-mounted camera-based approaches show promise in egocentric pose estimation, but encounter challenges when applied to VR head-mounted displays (HMDs), including temporal instability, inaccurate lower-body estimation, and the lack of real-time performance. To address these limitations, we present EgoPoseVR, an end-to-end framework for accurate egocentric full-body pose estimation in VR that integrates headset motion cues with egocentric RGB-D observations through a dual-modality fusion pipeline. A spatiotemporal encoder extracts frame- and joint-level representations, which are fused via cross-attention to fully exploit complementary motion cues across modalities. A kinematic optimization module then imposes constraints from HMD signals, enhancing the accuracy and stability of pose estimation. To facilitate training and evaluation, we introduce a large-scale synthetic dataset of over 1.8 million temporally aligned HMD and RGB-D frames across diverse VR scenarios. Experimental results show that EgoPoseVR outperforms state-of-the-art egocentric pose estimation models. A user study in real-world scenes further shows that EgoPoseVR achieved significantly higher subjective ratings in accuracy, stability, embodiment, and intention for future use compared to baseline methods. These results show that EgoPoseVR enables robust full-body pose tracking, offering a practical solution for accurate VR embodiment without requiring additional body-worn sensors or room-scale tracking systems.
Visual-Tactile Cross-Modal Data Generation using Residue-Fusion GAN with Feature-Matching and Perceptual Losses
Jul 12, 2021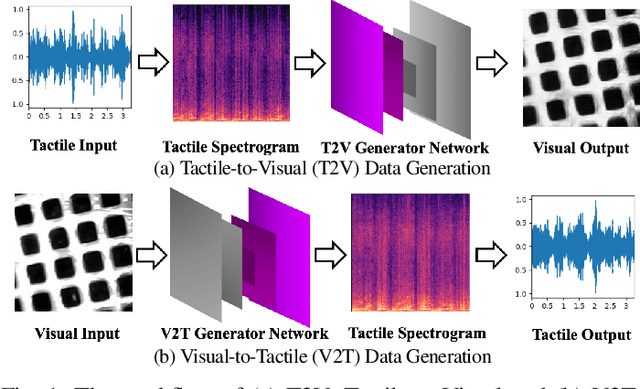
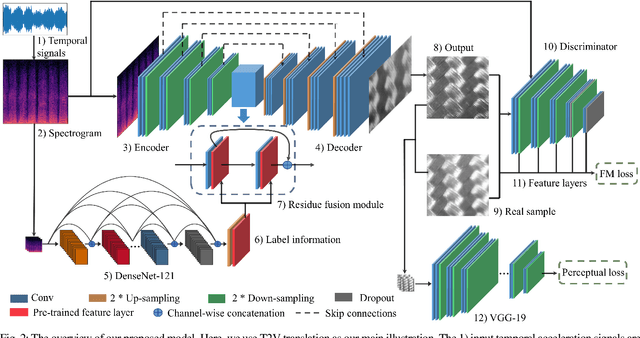
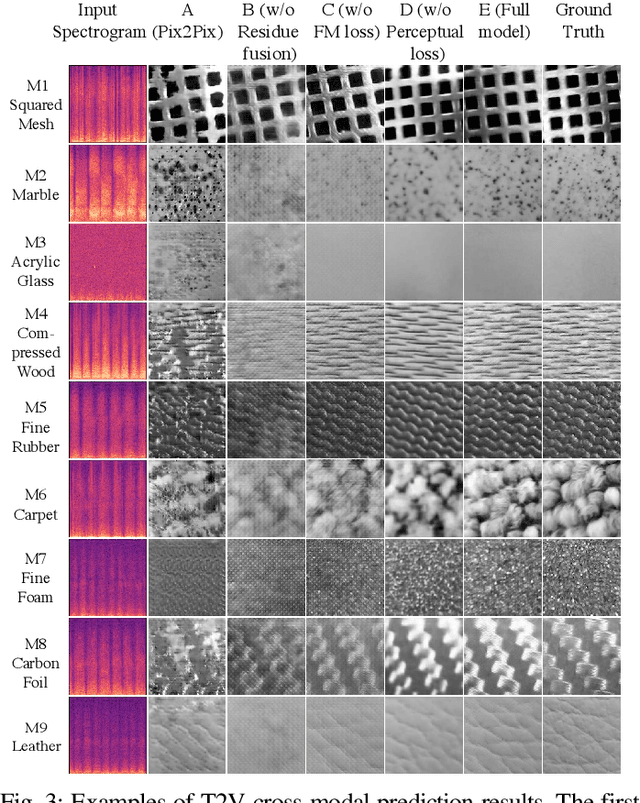
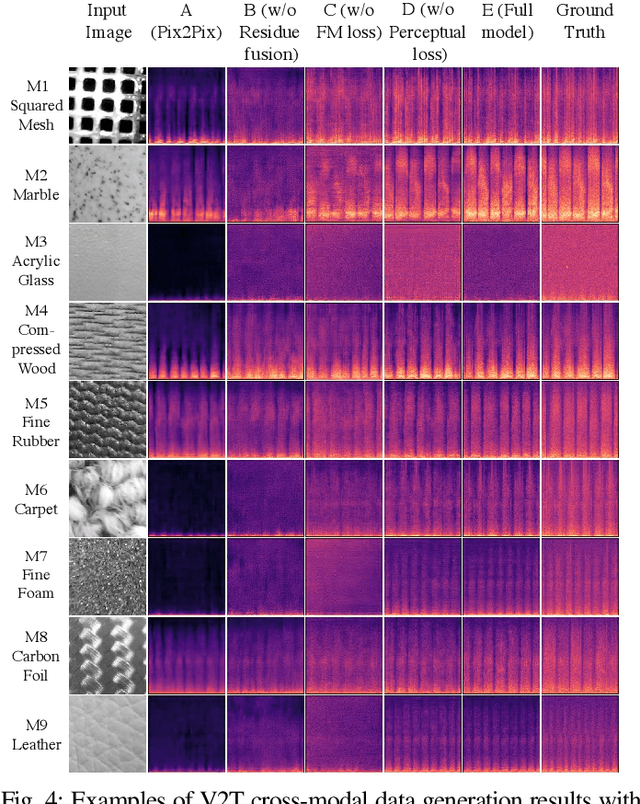
Existing psychophysical studies have revealed that the cross-modal visual-tactile perception is common for humans performing daily activities. However, it is still challenging to build the algorithmic mapping from one modality space to another, namely the cross-modal visual-tactile data translation/generation, which could be potentially important for robotic operation. In this paper, we propose a deep-learning-based approach for cross-modal visual-tactile data generation by leveraging the framework of the generative adversarial networks (GANs). Our approach takes the visual image of a material surface as the visual data, and the accelerometer signal induced by the pen-sliding movement on the surface as the tactile data. We adopt the conditional-GAN (cGAN) structure together with the residue-fusion (RF) module, and train the model with the additional feature-matching (FM) and perceptual losses to achieve the cross-modal data generation. The experimental results show that the inclusion of the RF module, and the FM and the perceptual losses significantly improves cross-modal data generation performance in terms of the classification accuracy upon the generated data and the visual similarity between the ground-truth and the generated data.