 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimitive Representation Learning for Scene Text Recognition
May 10, 2021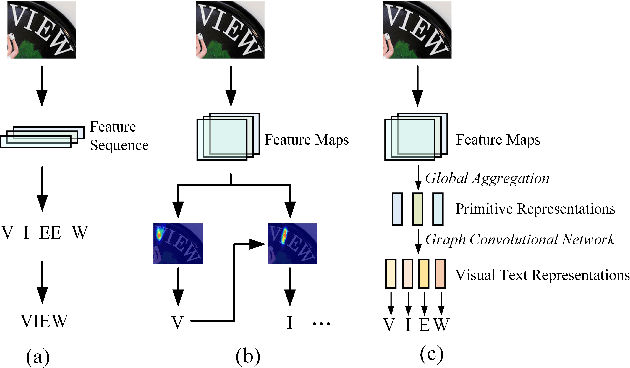
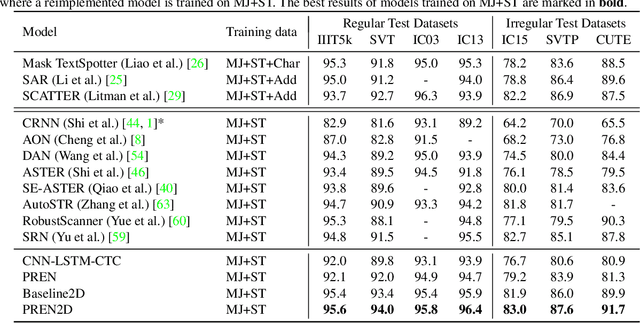
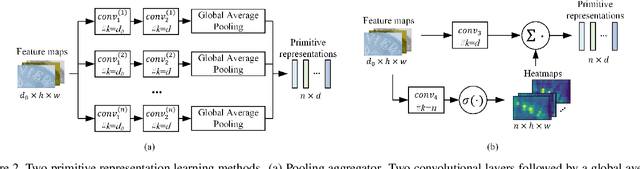

Scene text recognition is a challenging task due to diverse variations of text instances in natural scene images. Conventional methods based on CNN-RNN-CTC or encoder-decoder with attention mechanism may not fully investigate stable and efficient feature representations for multi-oriented scene texts. In this paper, we propose a primitive representation learning method that aims to exploit intrinsic representations of scene text images. We model elements in feature maps as the nodes of an undirected graph. A pooling aggregator and a weighted aggregator are proposed to learn primitive representations, which are transformed into high-level visual text representations by graph convolutional networks. A Primitive REpresentation learning Network (PREN) is constructed to use the visual text representations for parallel decoding. Furthermore, by integrating visual text representations into an encoder-decoder model with the 2D attention mechanism, we propose a framework called PREN2D to alleviate the misalignment problem in attention-based methods. Experimental results on both English and Chinese scene text recognition tasks demonstrate that PREN keeps a balance between accuracy and efficiency, while PREN2D achieves state-of-the-art performance.